Análisis de series de tiempo
Álvaro Paredes y Carlos Lara
20 Julio de 2017
1 Primeros pasos
Primero que todo, cargamos los datos nuevamente de trabajo (si es que no los tenemos listos ya):
df <- read.csv("EVI.csv", stringsAsFactors=F)
df$date <- as.Date(df$date, "%Y-%m-%d")
df$doy <- as.numeric(strftime(df$date, "%j"))
df$month <- as.numeric(strftime(df$date, "%m"))
df$year <- as.numeric(strftime(df$date, "%Y"))2 Descomposición
Veamos otra forma de obtener lo que ya hemos hecho hasta ahora
library(forecast)
sr <- ts(df$EVI, start=c(2000, 2), frequency=12) # Le decimos al programa directamente que esto es una serie de tiempo
sr## Jan Feb Mar Apr May Jun Jul
## 2000 0.3474081 0.4349093 0.3997135 0.3596721 0.3709763 0.3561040
## 2001 0.4945619 0.4516020 0.4408921 0.4310003 0.3484987 0.2717251 0.3855337
## 2002 0.4440724 0.4488392 0.3925600 0.3704686 0.3330891 0.4006768 0.3208705
## 2003 0.4349171 0.4756597 0.4359210 0.4153757 0.3952876 0.3737445 0.3872645
## 2004 0.4945951 0.4529529 0.4390505 0.4094688 0.3923723 0.3701430 0.3877779
## 2005 0.4631558 0.4728432 0.4180839 0.4139828 0.3771818 0.3763094 0.3834763
## 2006 0.4834812 0.4737765 0.4588530 0.4276008 0.3941900 0.3483986 0.3845868
## 2007 0.4798939 0.4579065 0.4290245 0.3937041 0.3860433 0.3834466 0.3875031
## 2008 0.4492491 0.4465749 0.4285926 0.4124794 0.3870819 0.3814352 0.3959369
## 2009 0.4606542 0.4118101 0.4339030 0.4210835 0.4011840 0.3313933 0.3877690
## 2010 0.4732513 0.4625712 0.4519794 0.4150563 0.4220769 0.3651925 0.4114572
## 2011 0.4797997 0.4594717 0.4360519 0.4271912 0.3838491 0.3998598 0.4008540
## 2012 0.4674790 0.4044663 0.4432875 0.4217237 0.3938309 0.3949420 0.4157545
## 2013 0.4688265 0.4454287 0.4458254 0.4358646 0.4137031 0.3928081 0.4221289
## 2014 0.4718179 0.4434580 0.4267898 0.4183619 0.3940085 0.4171483 0.4052965
## 2015 0.4670974 0.4606820 0.4168454 0.4282277 0.3865664 0.4139259 0.3962807
## 2016 0.4739392 0.4339906 0.4276451 0.4045628 0.4034853 0.4052441 0.3840768
## Aug Sep Oct Nov Dec
## 2000 0.3853246 0.3937942 0.4273154 0.4339750 0.4353144
## 2001 0.3909762 0.4159537 0.4543979 0.4548437 0.4611937
## 2002 0.3058704 0.3373443 0.3725168 0.4464700 0.4599764
## 2003 0.3891224 0.4008792 0.3490634 0.4237550 0.4124179
## 2004 0.3880223 0.3705904 0.3940603 0.4851220 0.4706059
## 2005 0.3982587 0.4394149 0.4118944 0.4593389 0.4817197
## 2006 0.4216852 0.3670107 0.4439169 0.4530323 0.4397168
## 2007 0.4032032 0.4127347 0.3596043 0.4582744 0.4622181
## 2008 0.4095516 0.4205192 0.4460430 0.4684586 0.4578048
## 2009 0.3807391 0.4161713 0.3797855 0.3872528 0.4547483
## 2010 0.4141361 0.4241326 0.4923984 0.4753043 0.4735738
## 2011 0.3990287 0.4200917 0.4306481 0.4356431 0.4879421
## 2012 0.4173493 0.4343012 0.4443471 0.4511595 0.4302173
## 2013 0.3957412 0.4339167 0.4254262 0.4798854 0.4582274
## 2014 0.4298701 0.3718523 0.4356760 0.4538341 0.4491317
## 2015 0.4201884 0.4310132 0.4236290 0.4846016 0.4815246
## 2016 0.3807446 0.4249608 0.4320328 0.4545806 0.4541745start(sr)## [1] 2000 2end(sr)## [1] 2016 12frequency(sr)## [1] 12cycle(sr)## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 2000 2 3 4 5 6 7 8 9 10 11 12
## 2001 1 2 3 4 5 6 7 8 9 10 11 12
## 2002 1 2 3 4 5 6 7 8 9 10 11 12
## 2003 1 2 3 4 5 6 7 8 9 10 11 12
## 2004 1 2 3 4 5 6 7 8 9 10 11 12
## 2005 1 2 3 4 5 6 7 8 9 10 11 12
## 2006 1 2 3 4 5 6 7 8 9 10 11 12
## 2007 1 2 3 4 5 6 7 8 9 10 11 12
## 2008 1 2 3 4 5 6 7 8 9 10 11 12
## 2009 1 2 3 4 5 6 7 8 9 10 11 12
## 2010 1 2 3 4 5 6 7 8 9 10 11 12
## 2011 1 2 3 4 5 6 7 8 9 10 11 12
## 2012 1 2 3 4 5 6 7 8 9 10 11 12
## 2013 1 2 3 4 5 6 7 8 9 10 11 12
## 2014 1 2 3 4 5 6 7 8 9 10 11 12
## 2015 1 2 3 4 5 6 7 8 9 10 11 12
## 2016 1 2 3 4 5 6 7 8 9 10 11 12plot(sr)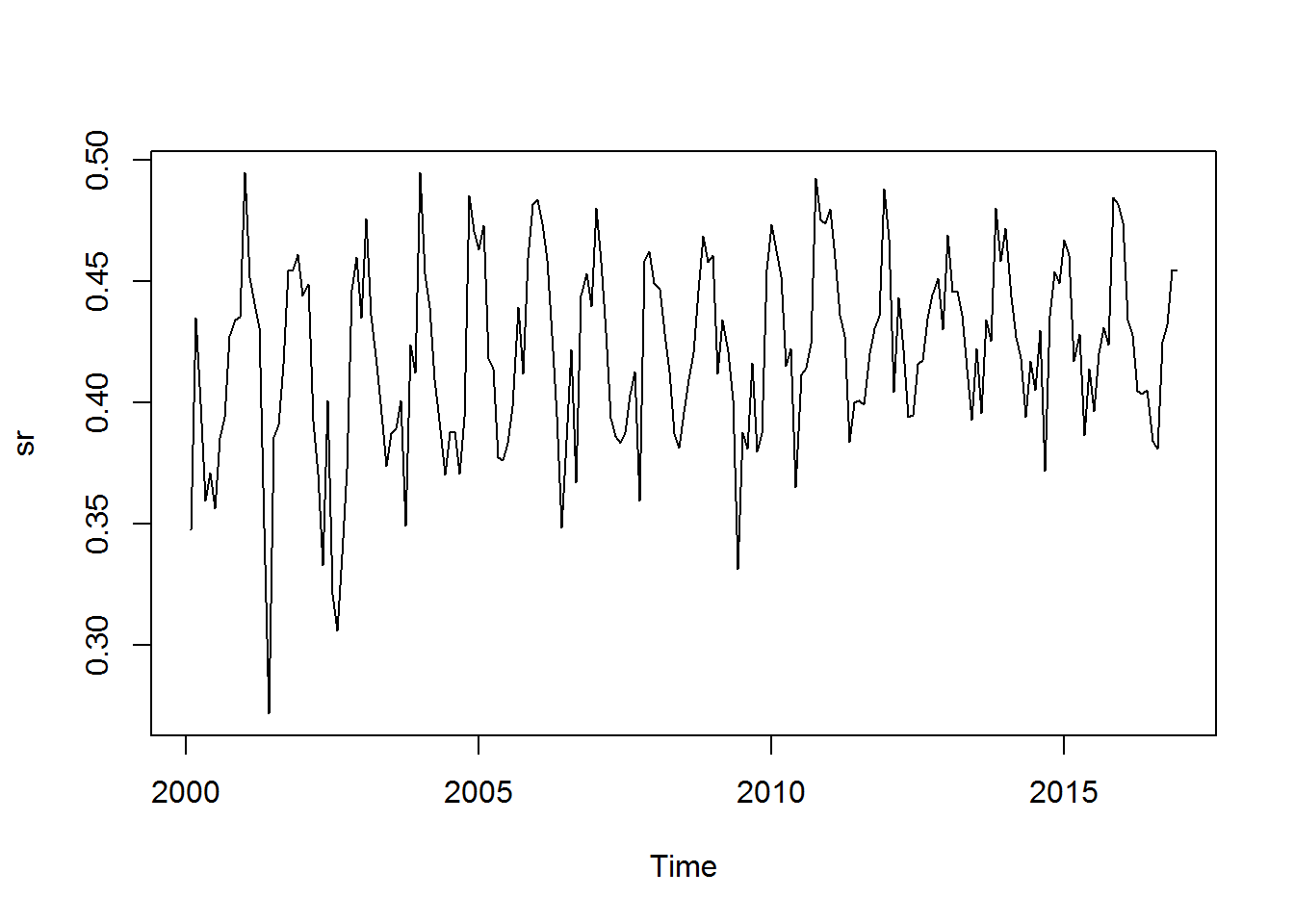
boxplot(sr ~ cycle(sr))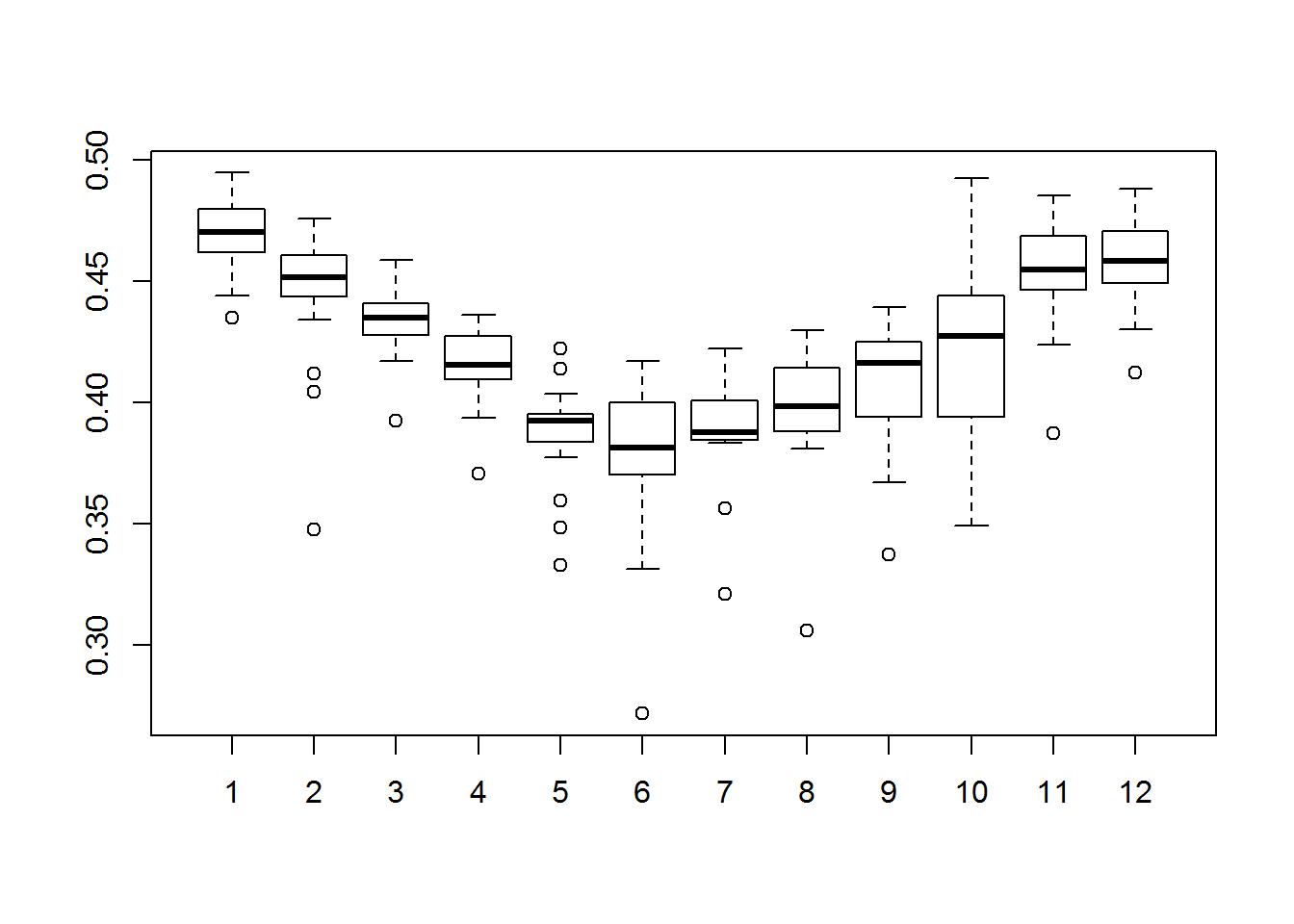
Los gráficos que logramos producir anteriormente, se producen de manera más simple si ya utilizamos las funciones diseñadas para series de tiempo. De esta forma, podemos ver rápidamente la descomposición de la serie de tiempo para observar la tendencia, el comportamiento estacional y la componente aleatoria.
Unas serie de tiempo puede ser aditiva o multiplicativa. En este caso es aditiva (un ejemplo de una serie multiplicativa pueden ser las ventas de automóviles en el mundo, desde 1940 al 2000). La serie está compuesta por: \[Y_t = Tendencia_t + Estacionalidad_t + Ruido_t \] para las series aditivas y para las series multiplicativas: \[Y_t = Tendencia_t * Estacionalidad_t * Ruido_t \]
des_sr <- decompose(sr, type="additive") # o "multiplicative"
str(des_sr)## List of 6
## $ x : Time-Series [1:203] from 2000 to 2017: 0.347 0.435 0.4 0.36 0.371 ...
## $ seasonal: Time-Series [1:203] from 2000 to 2017: 0.02875 0.01138 -0.00616 -0.03333 -0.04506 ...
## $ trend : Time-Series [1:203] from 2000 to 2017: NA NA NA NA NA ...
## $ random : Time-Series [1:203] from 2000 to 2017: NA NA NA NA NA ...
## $ figure : num [1:12] 0.02875 0.01138 -0.00616 -0.03333 -0.04506 ...
## $ type : chr "additive"
## - attr(*, "class")= chr "decomposed.ts"plot(des_sr)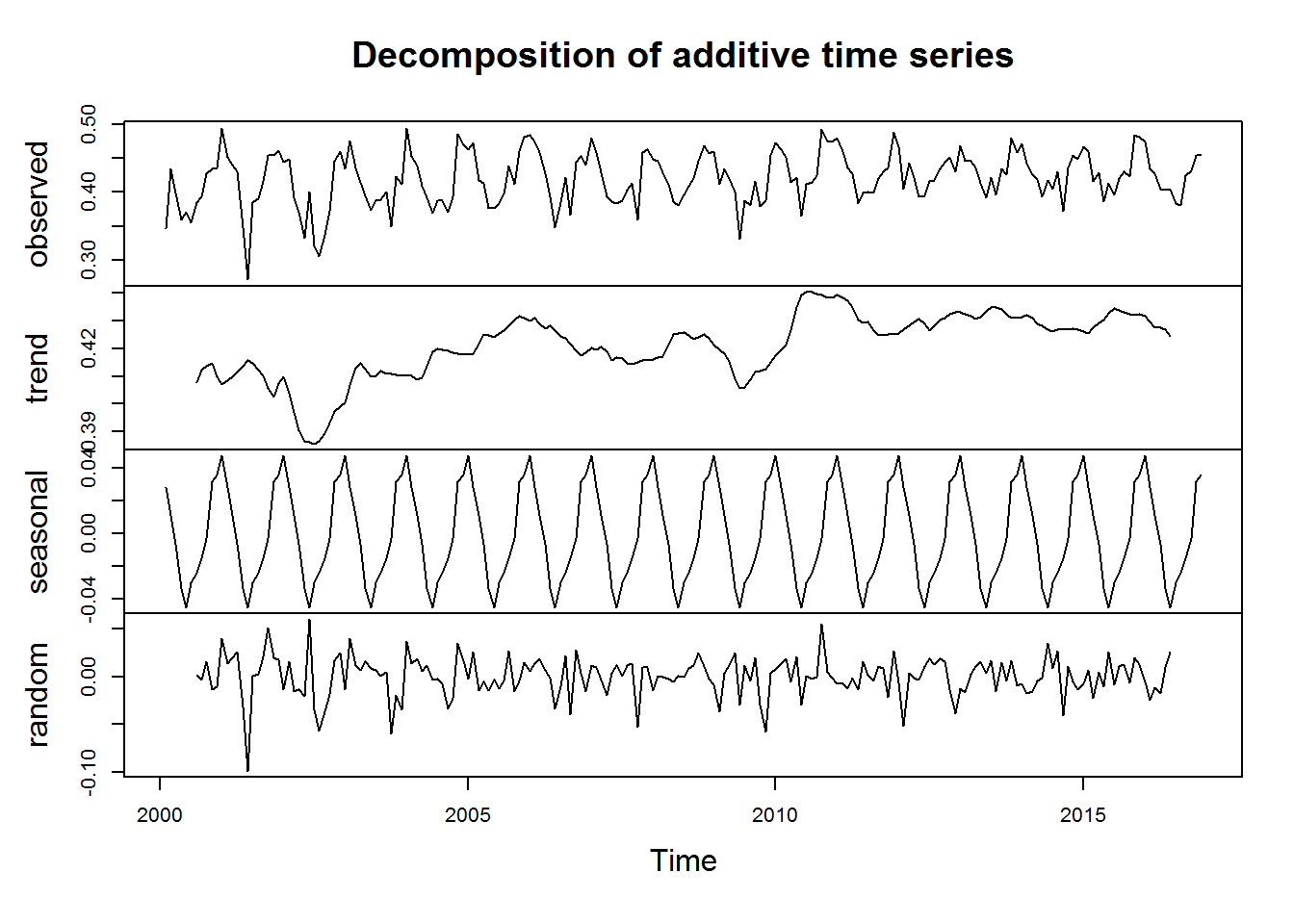
Con esto podemos separar la señal y ver si los cambios que tenemos son debido a una estacionalidad, a la tendencia o se deben a algo más (ruido). Por ejemplo, las ventas de helados de seguro bajan en cada época invernal dentro del año, pero eso no significa que quienes vendan helado lo estén haciendo mal. Para la vegetación y los sistemas productivos, ocurre lo mismo ¿El aumento en la productividad de la vegetación en verano es algo estacinonal o tiene otras causantes?
2.1 Medias móviles
Permite identificar el patrón “resumen” de los datos (o la tendencia). Miremos por ejemplo el siguiente gráfico:
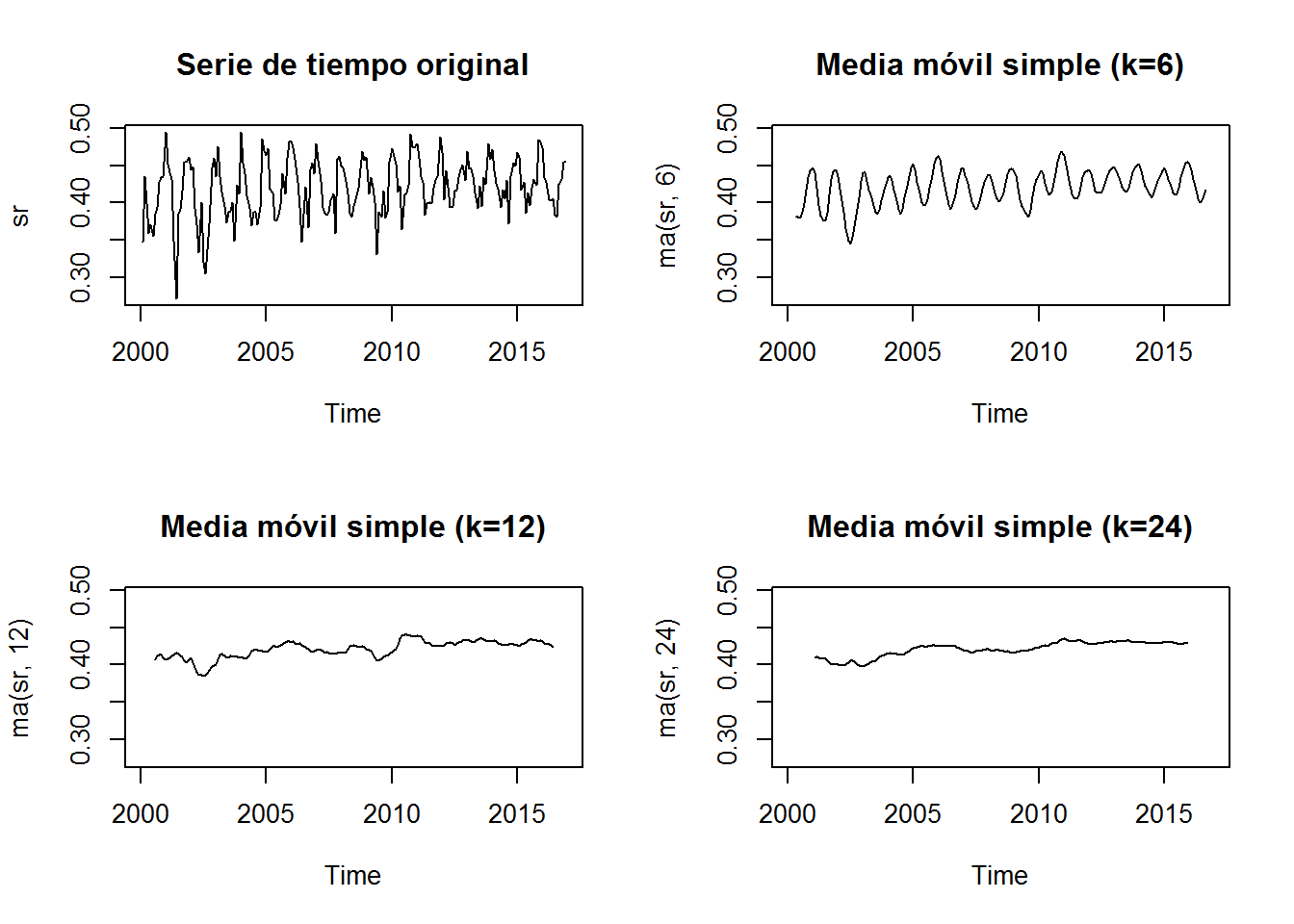
La función ma es la encargada de suavizar los datos y eliminar el ruido de la señal. El principal argumento de esta función es order que significa el orden de la media móvil (o tamaño del filtro). Para el ejemplo anterior tenemos 6, 12 y 24, que siendo la señal analizada una serie de datos mensuales, correspondería a los meses. Por dicha razón, 12 vendría siendo el ciclo anual para nustra serie actual. Podemos probar e intentar replicar el gráfico anterior:
par(mfrow=c(1,2))
ylim <- range(sr)
plot(sr, main="Serie de tiempo original")
plot(ma(sr, 12), main="Media móvil simple (k=12)", ylim=ylim)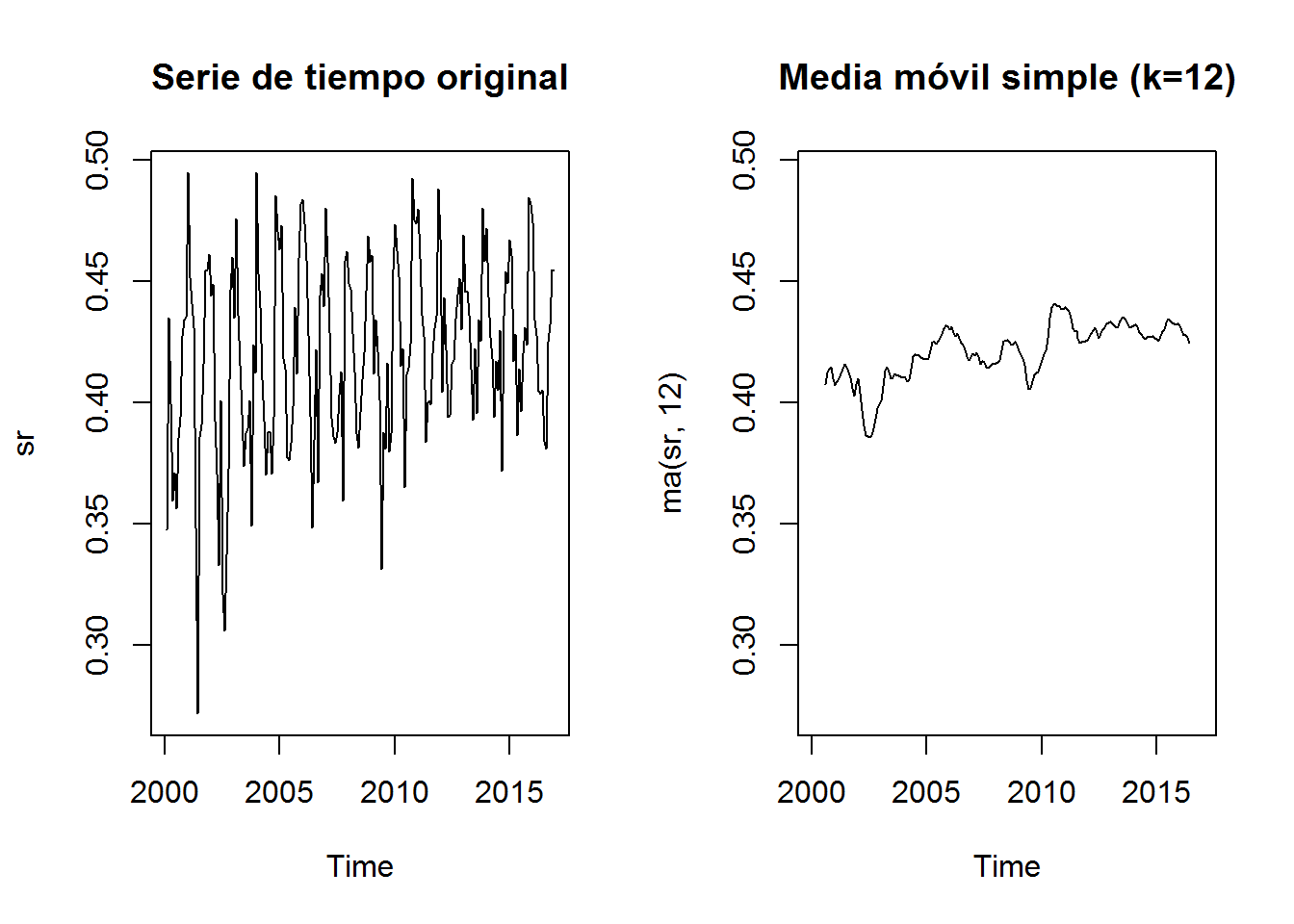
par(mfrow=c(1,1))Y en líneas generales, podemos eliminar la tendencia de una señal dada, si restamos la media móvil a la señal original
sm <- ma(sr, order=12)
plot(sr-sm)
par(new=TRUE)
plot(sm, col="red", lwd=2, xaxt="n", yaxt="n", xlab="", ylab="")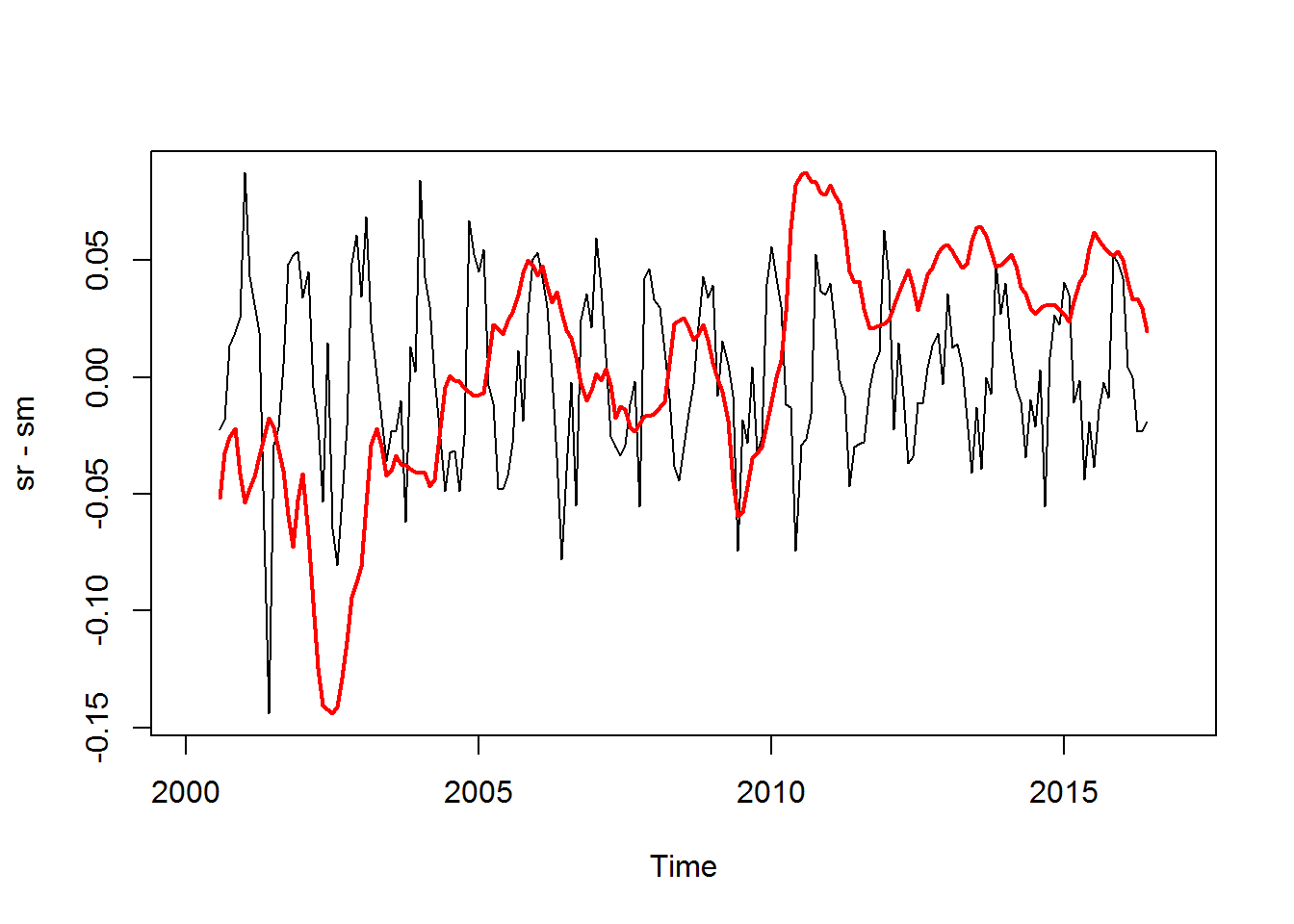
par(new=FALSE) # Para dejar todo como estaba2.2 Estacionalidad
Manualmente también podemos generar estas series y en varios casos resulta mejor, pues hay un mayor control sobre lo que se está haciendo. Veamos primero el ciclo estacional. Sí sabemos que debería existir un ciclo anual sobre nuestra serie, podemos generar el agregado de 12 meses o la climatología. Y de paso introducimos otra funcionalidad de R.
season <- aggregate(list(EVI=sr-sm), by=list(month=df$month), mean, na.rm=T)
plot(season$EVI, type="l")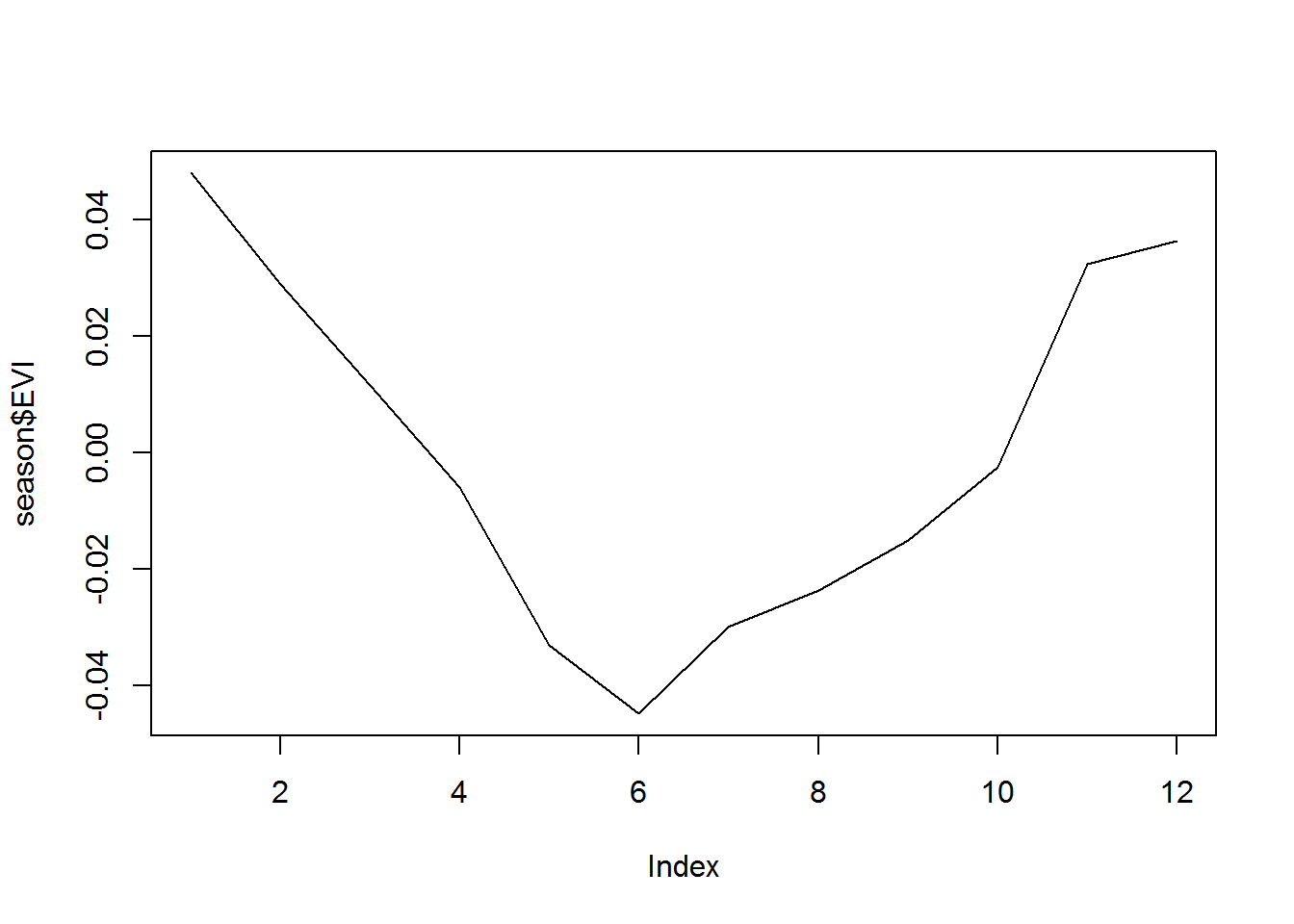
plot(df$date, rep(season$EVI, length(unique(df$year)))[-1], type="l")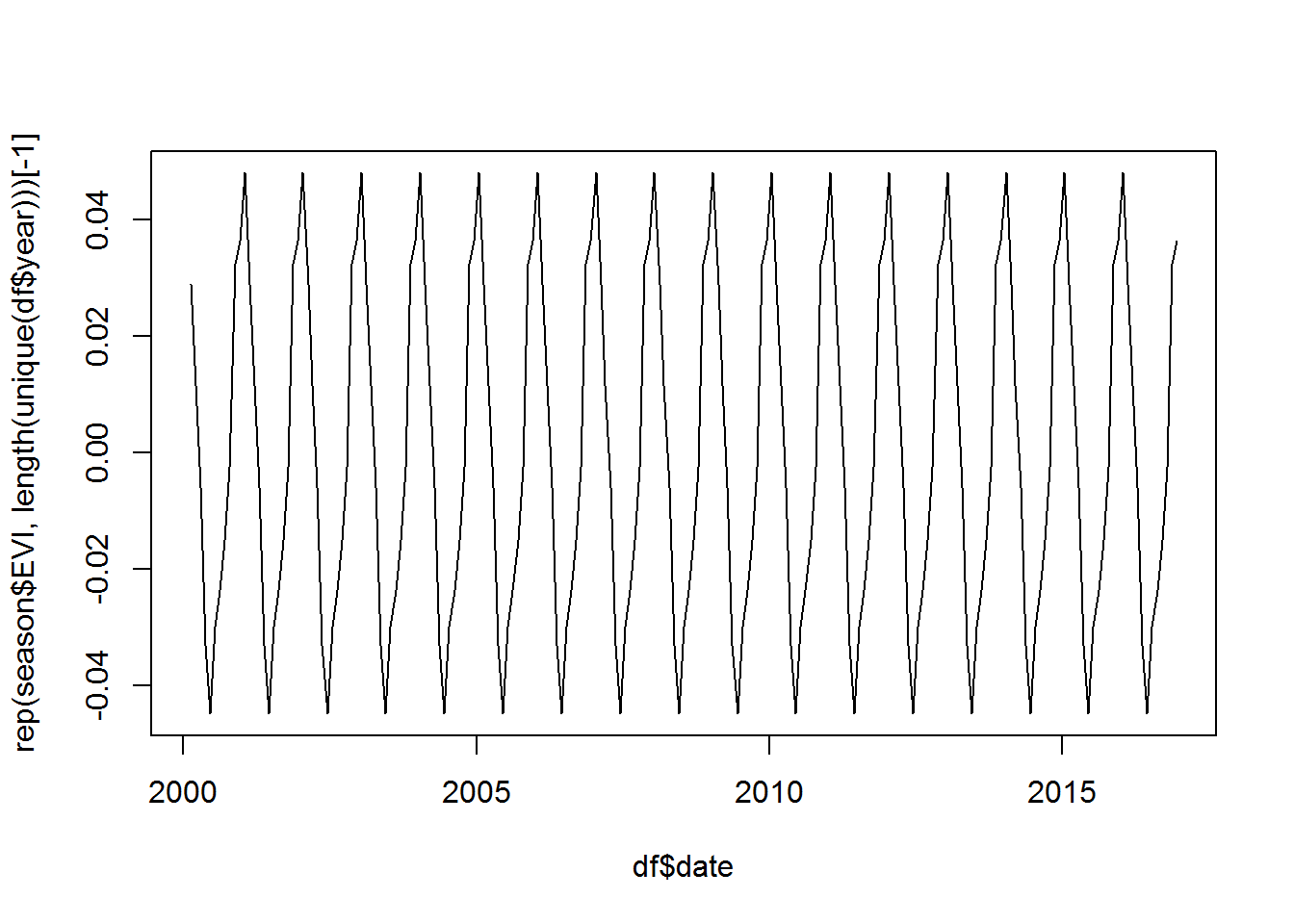
# ¿Qué tal nos va contra el resultado de la función?
plot(des_sr$seasonal)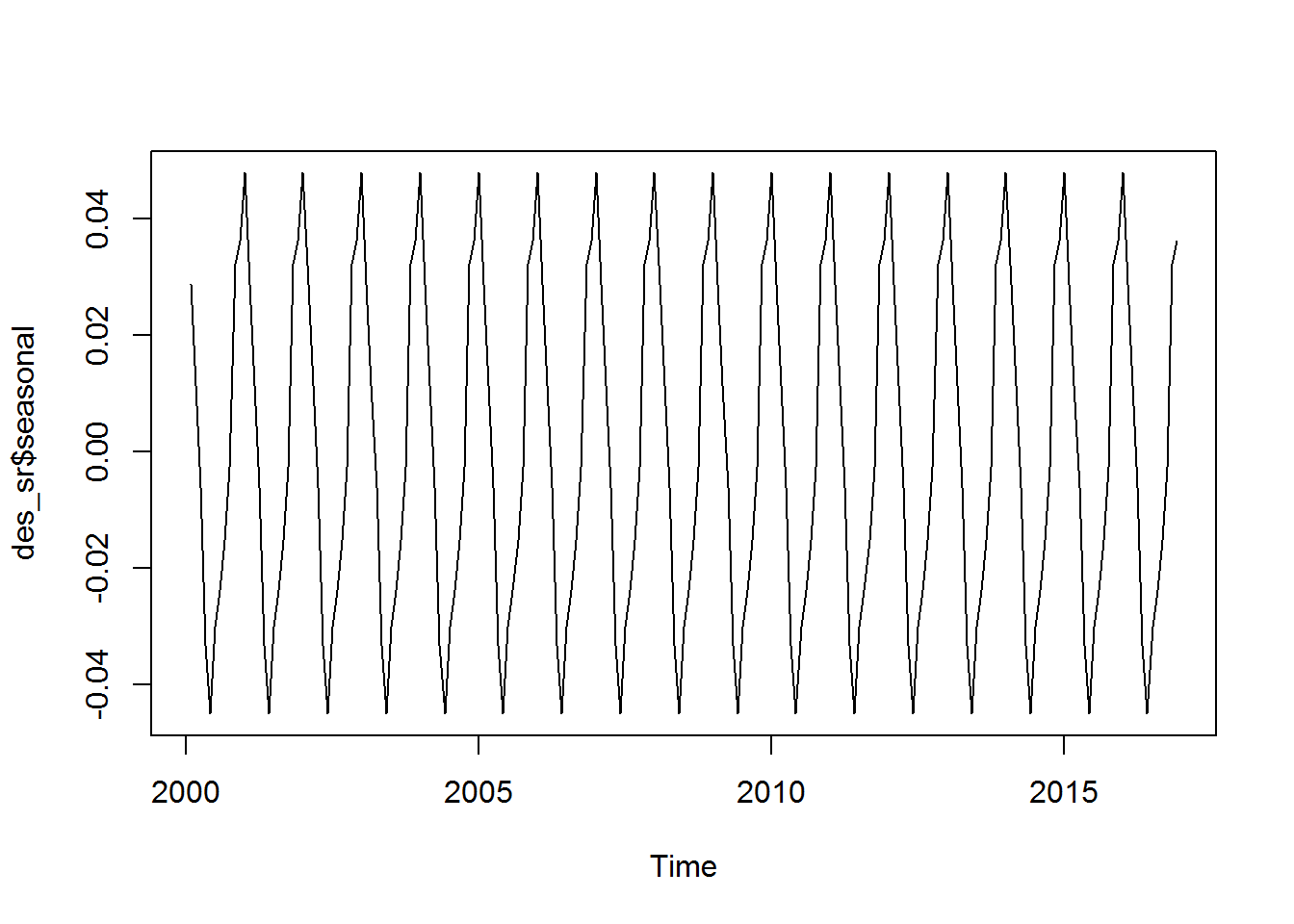
¿Notan alguna diferencia entre ambos gráficos?
2.3 Ruido
Si la serie de tiempo como esta, es aditiva, lo que queda de restar la estacionalidad y la tendencia, es el ruido.
season_sr <- ts(rep(season$EVI, length(unique(df$year)))[-1], start=c(2000, 2), frequency=12)
noise <- sr-sm-season_sr
plot(noise)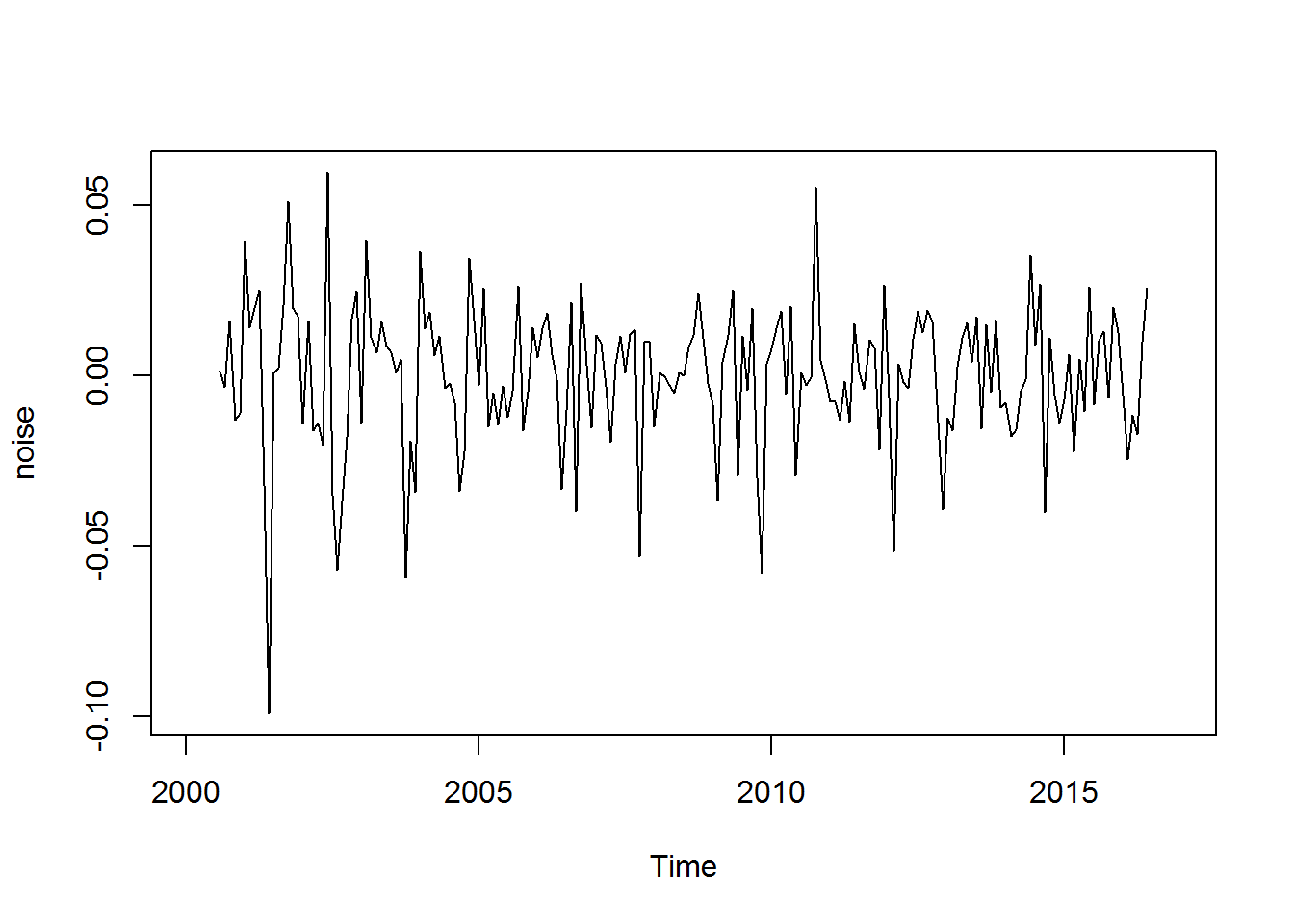
2.4 Reconstruyendo
Comparemos nuestros objetos season_sr, sm y noise, con respecto a la descomposición des_sr (generada por la función decompose). Veamos como nos va con un gráfico similar y luego revisamos los valores:
par(mfrow=c(2,1))
plot(sm, main="Media móvil 'manual'")
plot(des_sr$trend, main="Media móvil 'decompose'")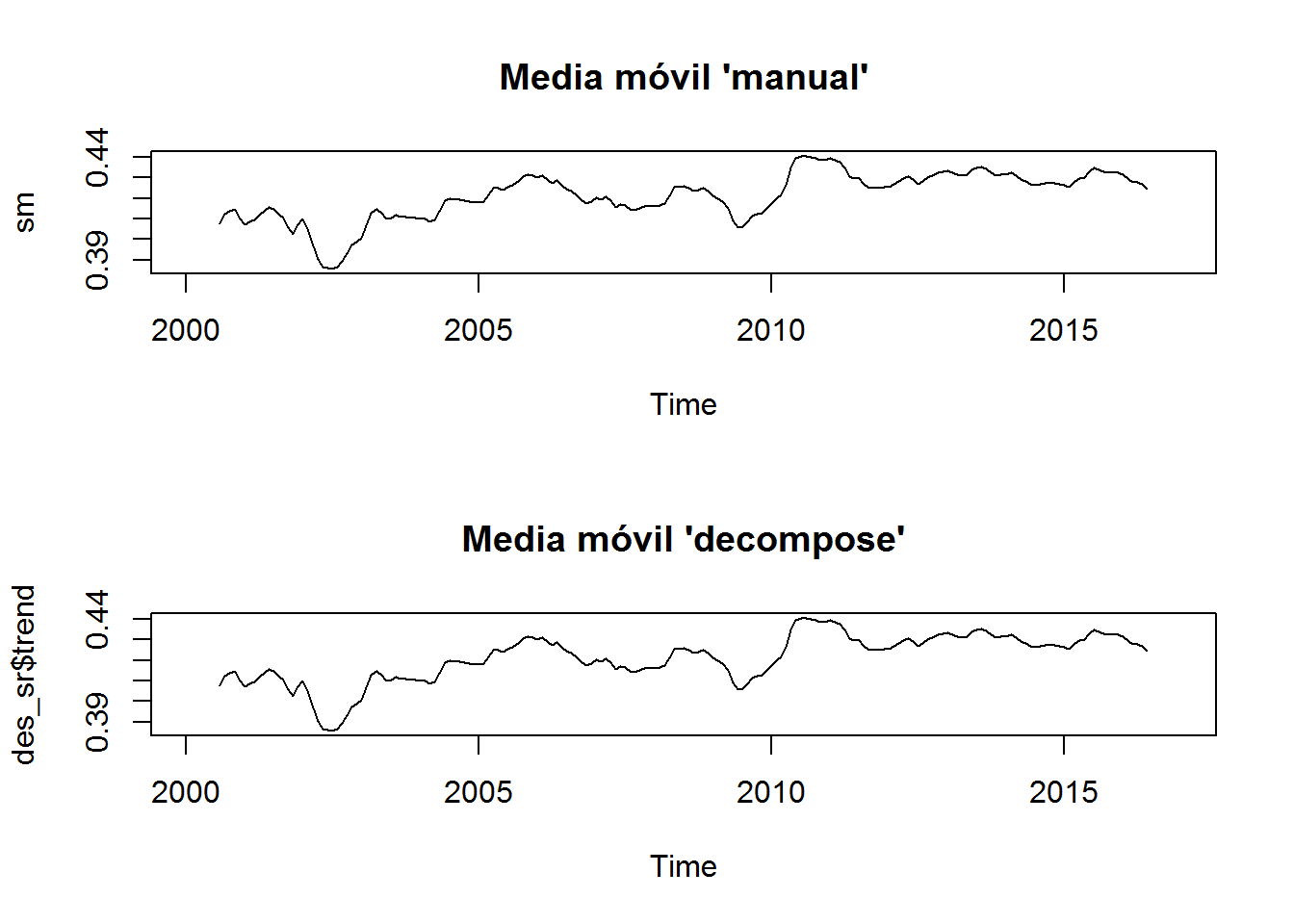
Hasta ahora bien…
plot(season_sr, main="Estacionalidad 'manual'")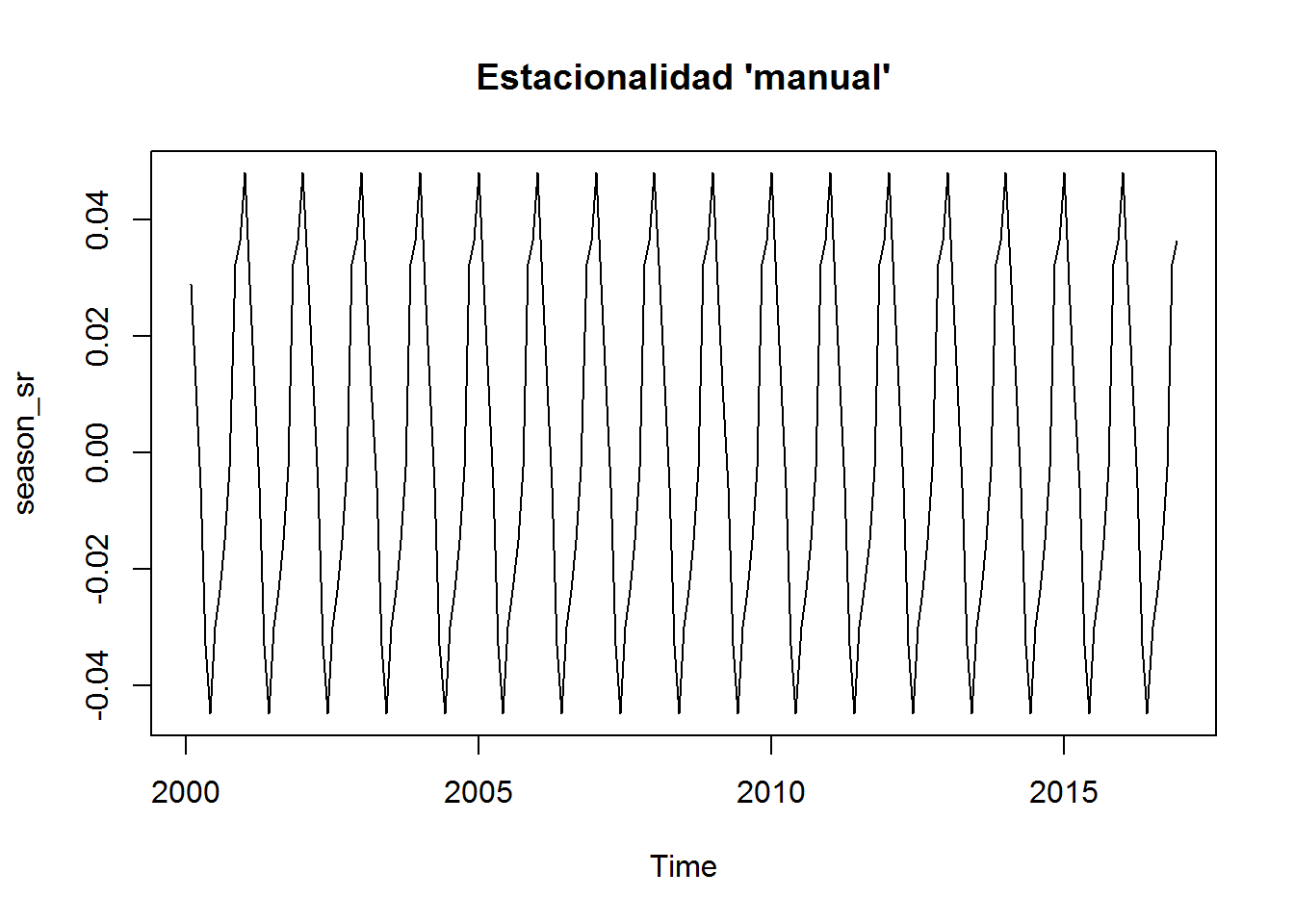
plot(des_sr$seasonal, main="Estacionalidad 'decompose'")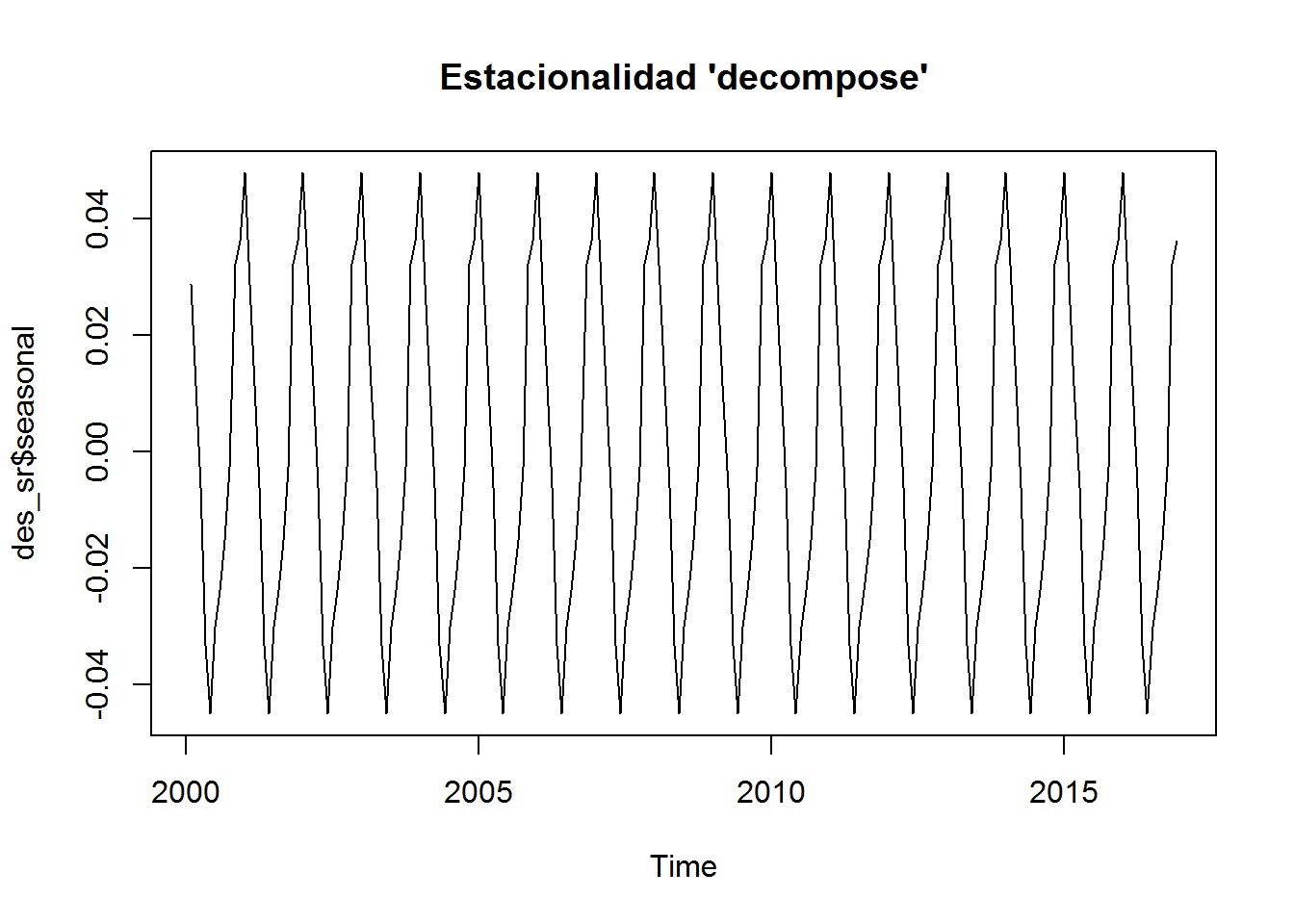
Una más…
plot(noise, main="Ruido 'manual'")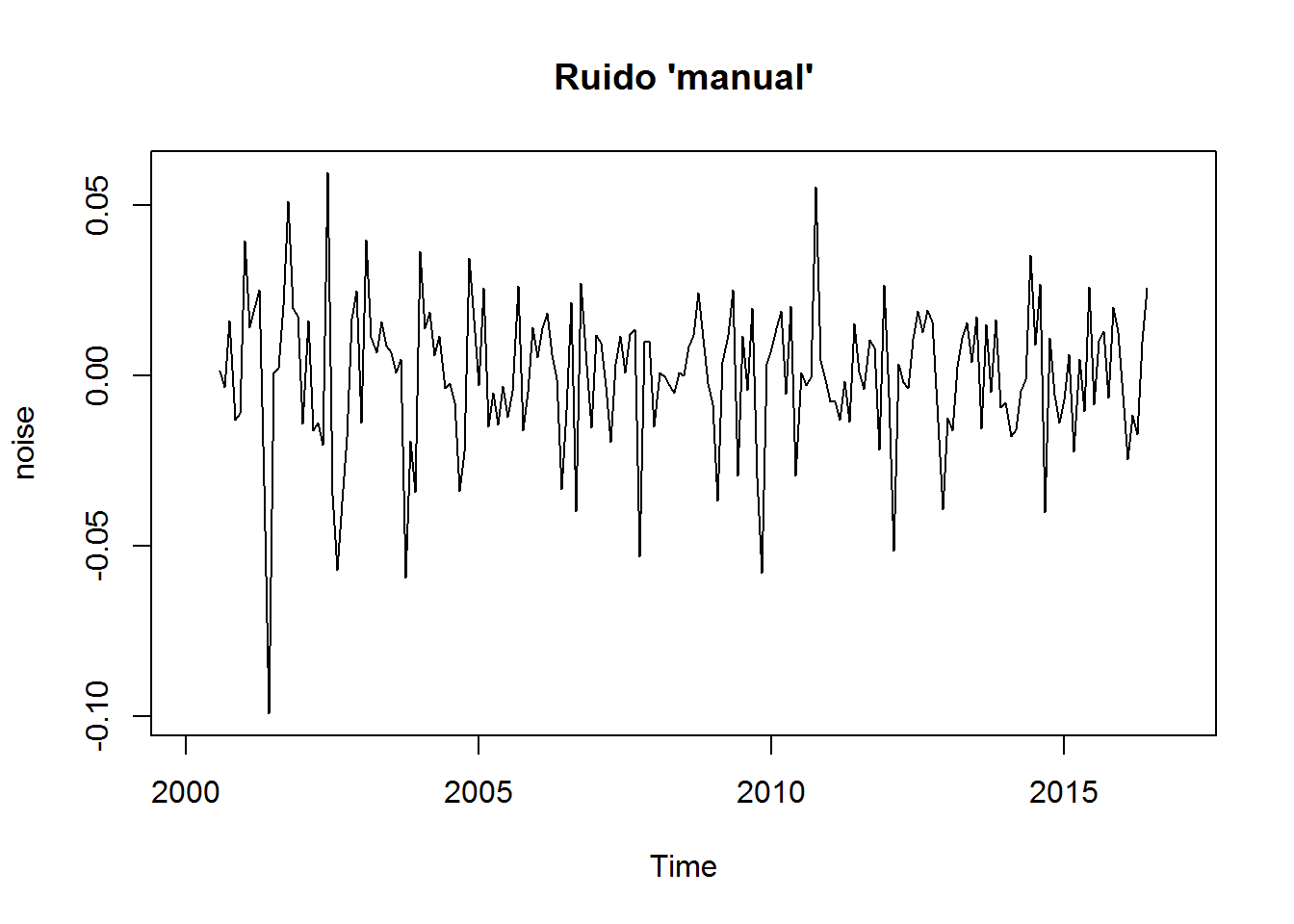
plot(des_sr$random, main="Ruido 'decompose'")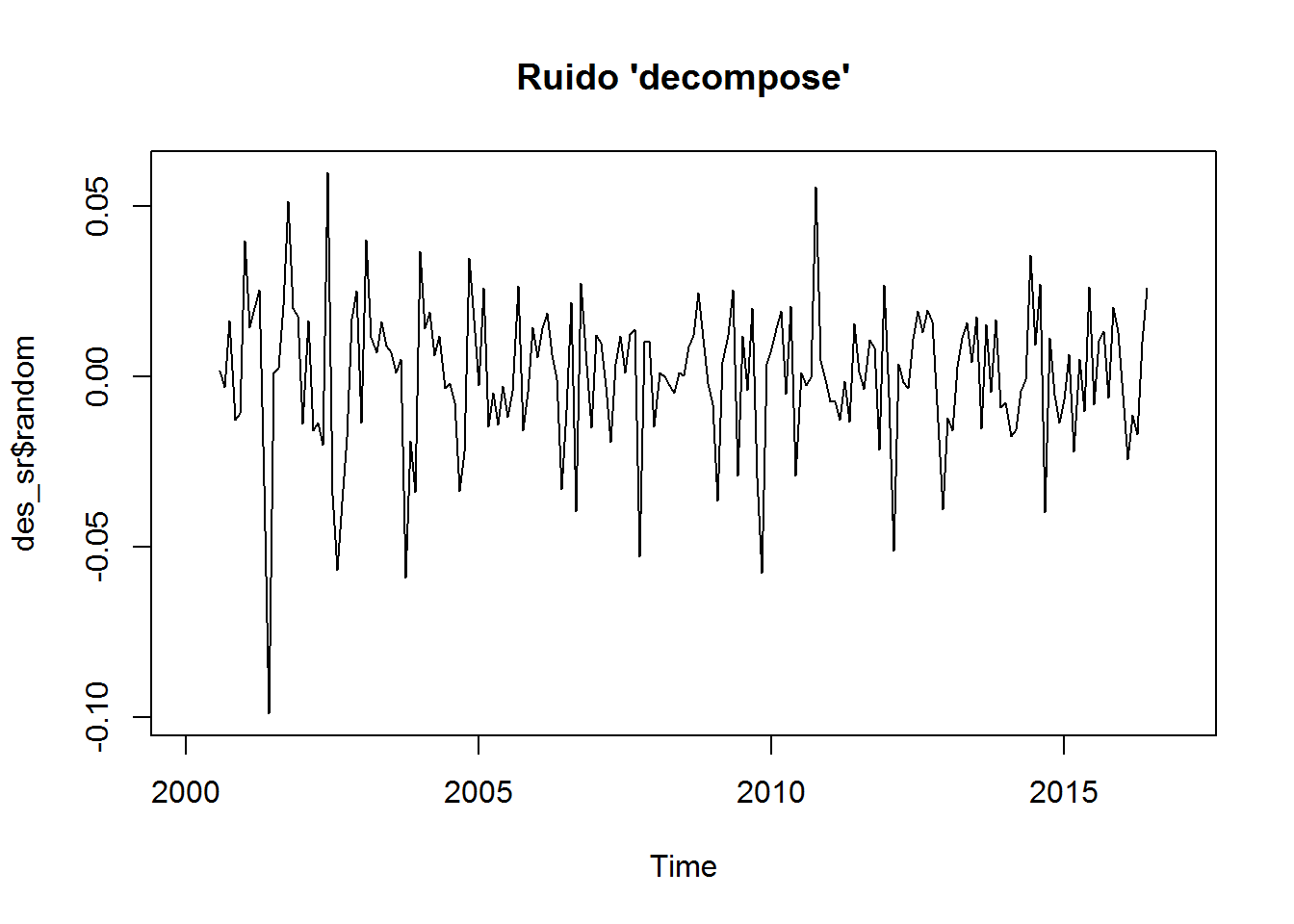
par(mfrow=c(1,1)) # Resetar los dos gráficos por panelAhora hay que comprarlas númericamente, viendo la diferencia entre ambas; por ejemplo, para la media móvil:
head(sm - des_sr$trend, 30)## Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
## 2000 NA NA NA NA NA NA 0 0 0 0 0
## 2001 0 0 0 0 0 0 0 0 0 0 0 0
## 2002 0 0 0 0 0 0 0all(sm == des_sr$trend, na.rm = T)## [1] TRUE¿Qué pasa con la estacionalidad y el ruido?
2.5 Transformación log
La transformación logarítmica puede usarse para controlar de mejor forma el incremento multiplicativo que pueden tener alguna series de tiempo.
log_sr <- log(sr)
plot(log(sr))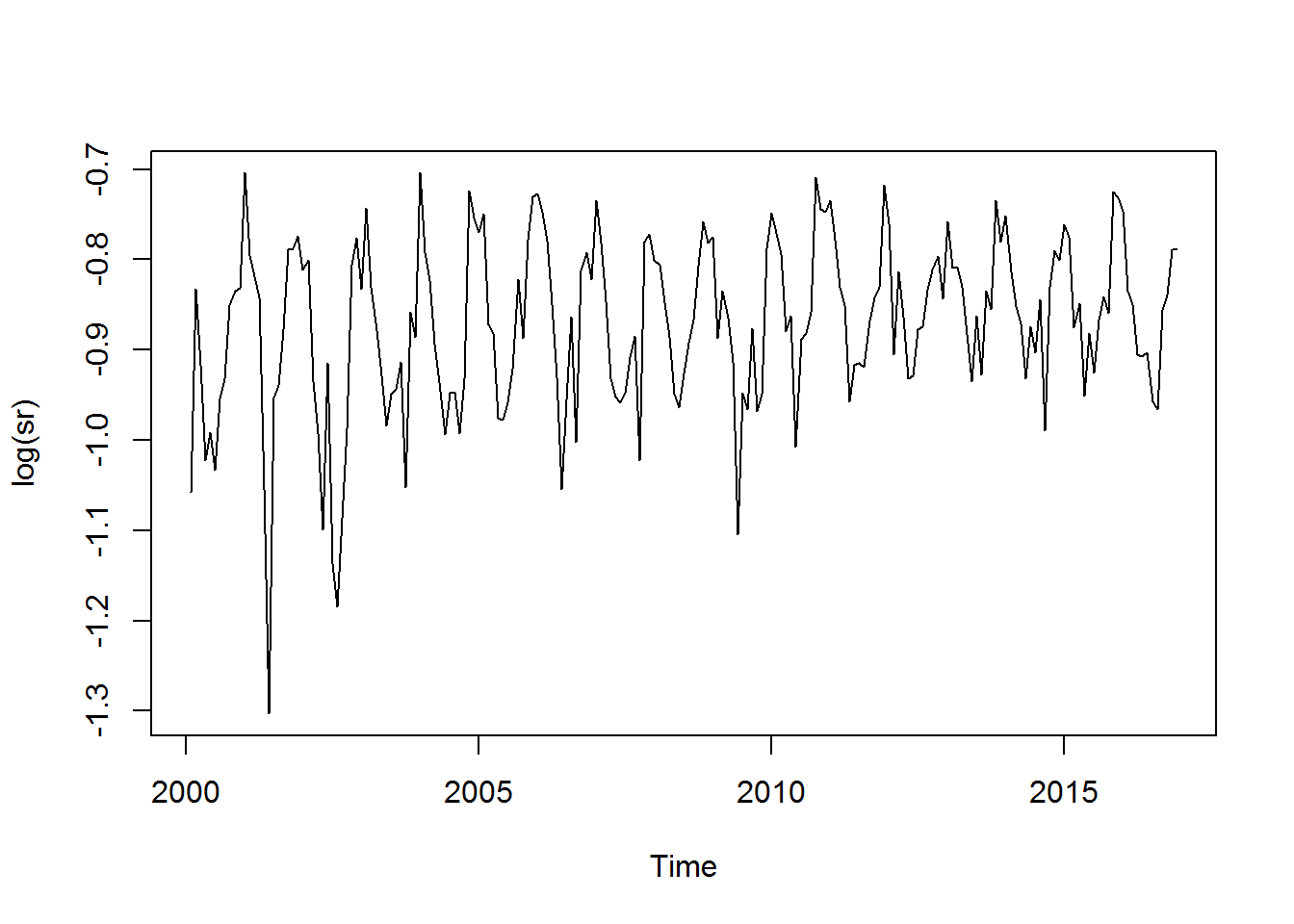
Por cierto:
\[ log(Y_i) = log(Tendencia_t * Estacionalidad_t * Ruido_t) = log(Tendencia_t) + log(Estacionalidad_t) + log(Ruido_t)\]
2.6 Una mejor alternativa
La función stl permite mayor flexibilidad. Eso sí, no admite series de tiempo multiplicativas, pero estos casos son los menores (y la solución la tenemos en el apartado anterior sobre transformación logarítmica). La mayor flexibilidad viene con el costo de tener muchas opciones de configuración.
stl_sr <- stl(sr, s.window="period")
str(stl_sr)## List of 8
## $ time.series: Time-Series [1:203, 1:3] from 2000 to 2017: 0.02502 0.01355 -0.00528 -0.0334 -0.04393 ...
## ..- attr(*, "dimnames")=List of 2
## .. ..$ : NULL
## .. ..$ : chr [1:3] "seasonal" "trend" "remainder"
## $ weights : num [1:203] 1 1 1 1 1 1 1 1 1 1 ...
## $ call : language stl(x = sr, s.window = "period")
## $ win : Named num [1:3] 2031 19 13
## ..- attr(*, "names")= chr [1:3] "s" "t" "l"
## $ deg : Named int [1:3] 0 1 1
## ..- attr(*, "names")= chr [1:3] "s" "t" "l"
## $ jump : Named num [1:3] 204 2 2
## ..- attr(*, "names")= chr [1:3] "s" "t" "l"
## $ inner : int 2
## $ outer : int 0
## - attr(*, "class")= chr "stl"plot(stl_sr)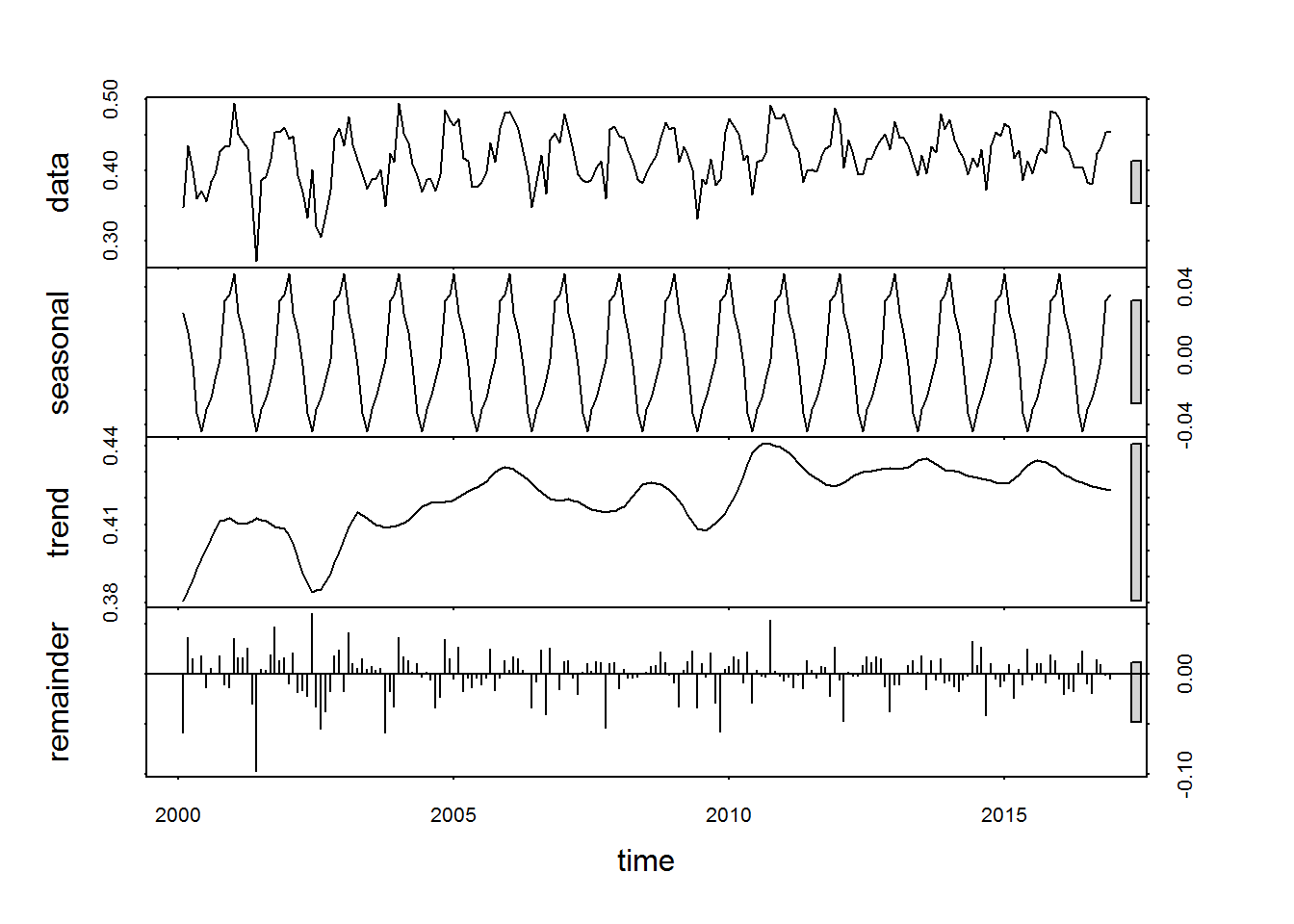
stl_sr12 <- stl(sr, 12)
plot(stl_sr12)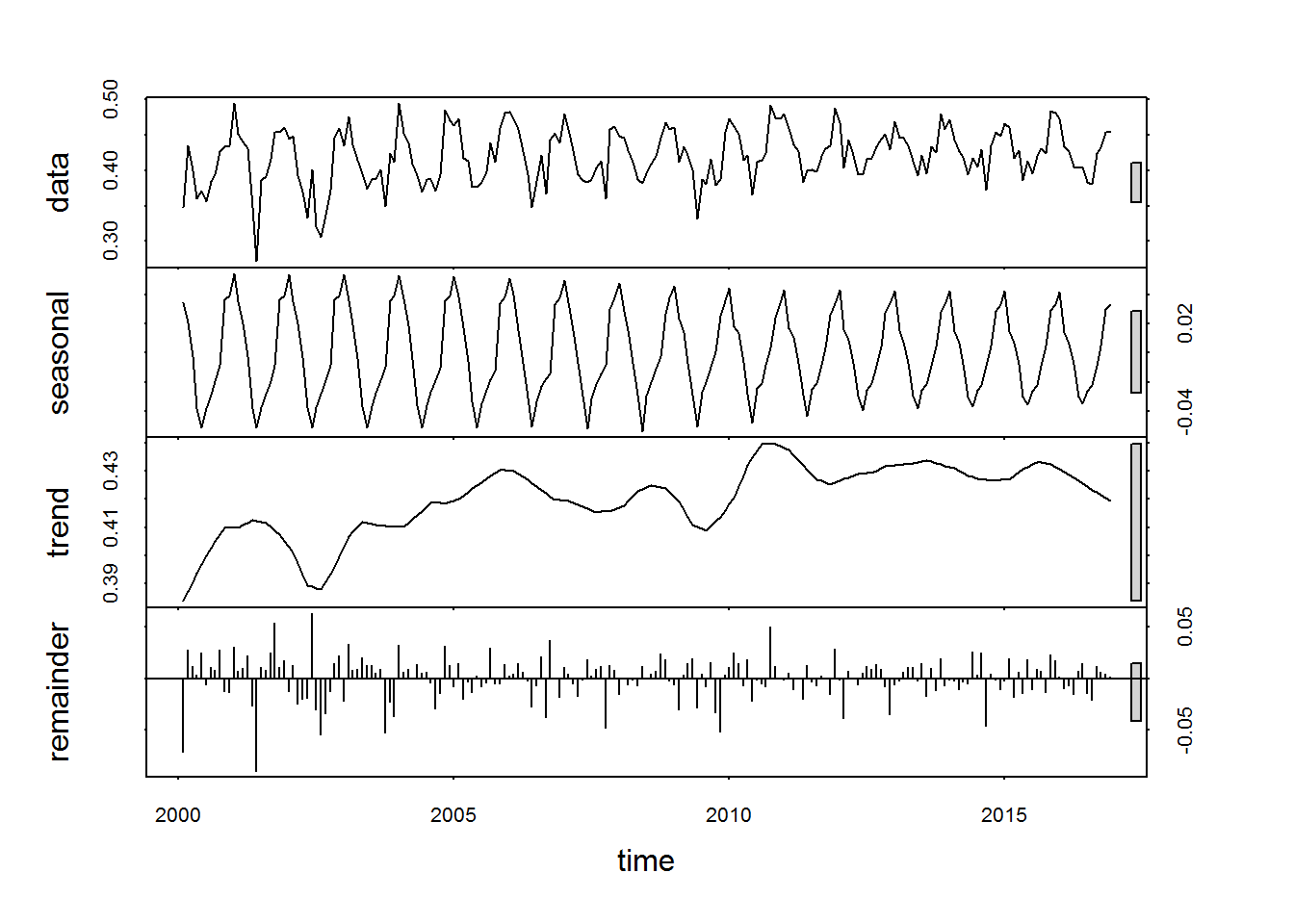
Con la opción “periodic” el resultado es similar a decompose, pues extrae la información estacional (del año) por medio de la media anual de 12 meses. En cambio, pasando el tamaño del filtro deseado (12 meses en este caso), se utiliza una estacionalidad que no se repite entre años. Luego podemos acceder a los datos completos, sin necesidad de calcularlos por nosotros mismos (¡y sin valores perdidos!)
head(stl_sr$time.series, 12)## seasonal trend remainder
## Feb 2000 0.025020207 0.3808130 -0.05842509438
## Mar 2000 0.013552583 0.3849184 0.03643830321
## Apr 2000 -0.005275097 0.3890238 0.01596478731
## May 2000 -0.033398123 0.3929896 0.00008063759
## Jun 2000 -0.043933316 0.3969554 0.01795425089
## Jul 2000 -0.031429979 0.4007684 -0.01323442314
## Aug 2000 -0.024700824 0.4045814 0.00544400408
## Sep 2000 -0.013971896 0.4078788 -0.00011266373
## Oct 2000 -0.001877938 0.4111762 0.01801712252
## Nov 2000 0.032225860 0.4117593 -0.01001012082
## Dec 2000 0.035870875 0.4123423 -0.01289883219
## Jan 2001 0.047917650 0.4112526 0.03539172196Y podemos obtener un poco más de ayuda de esta función:
monthplot(stl_sr)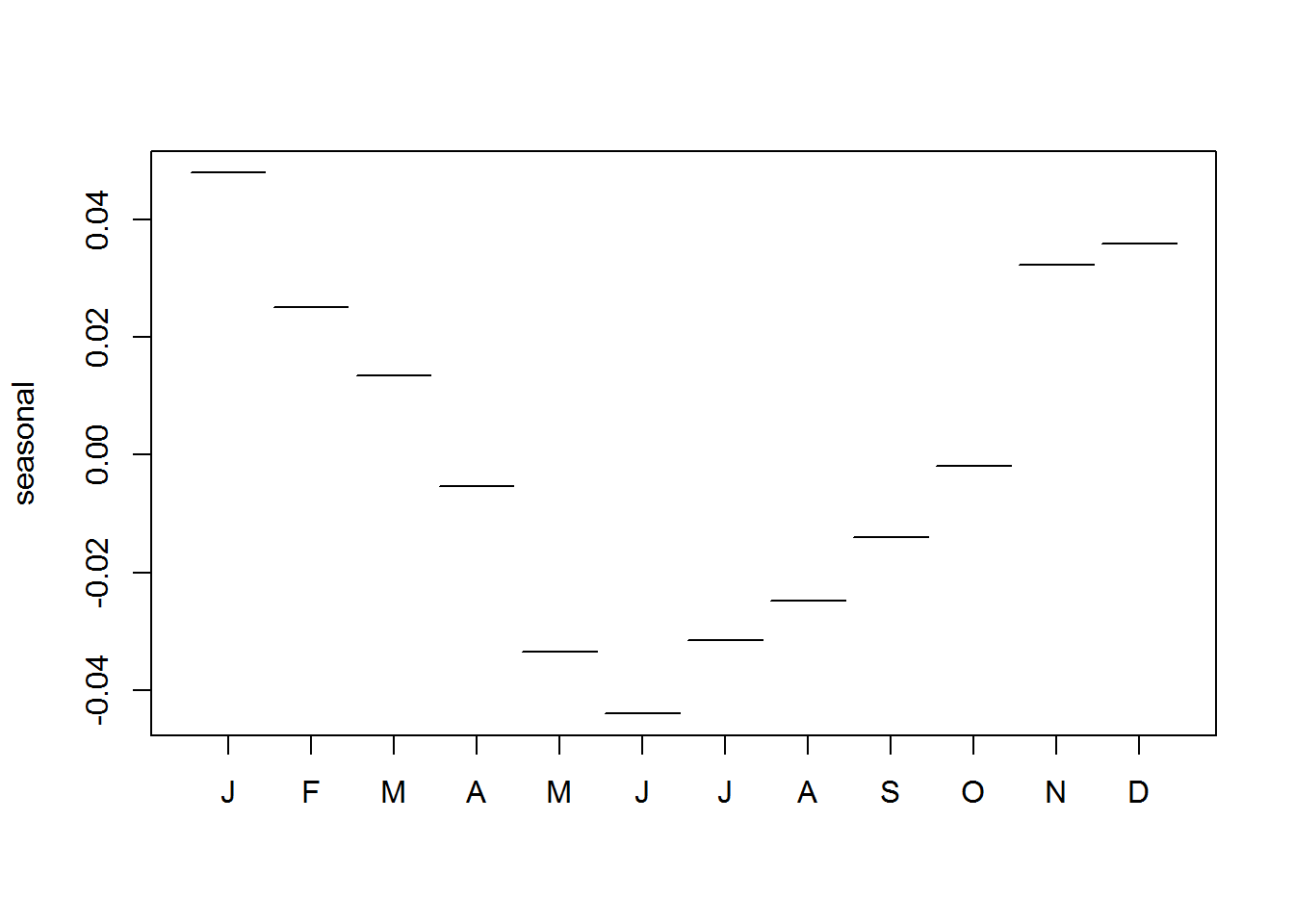
monthplot(stl_sr12)
3 Modelos estacionarios autoregresivos
Ahora intentemos ver como producir un modelo para predecir los valores futuros de la serie. Para eso, tenemos que tener lo siguiente:
- Asegurarnos que la serie de tiempo sea estacionaria
- Identificar un modelo razonable
- Ajustar el modelo
- Evaluar el modelo
- Predecir
3.1 ARIMA
Utilizaremos el model ARIMA (Autoregressive Integrated Moving Average). Primero, revisamos estacionalidad:
par(mfrow=c(2,1))
plot(sr)
ndiffs(sr) # ¿Cuánto lag es necesario para hacer la serie estacionaria?## [1] 1dsr <- diff(sr) # Pues solo necesitamos 1 como lag
plot(dsr)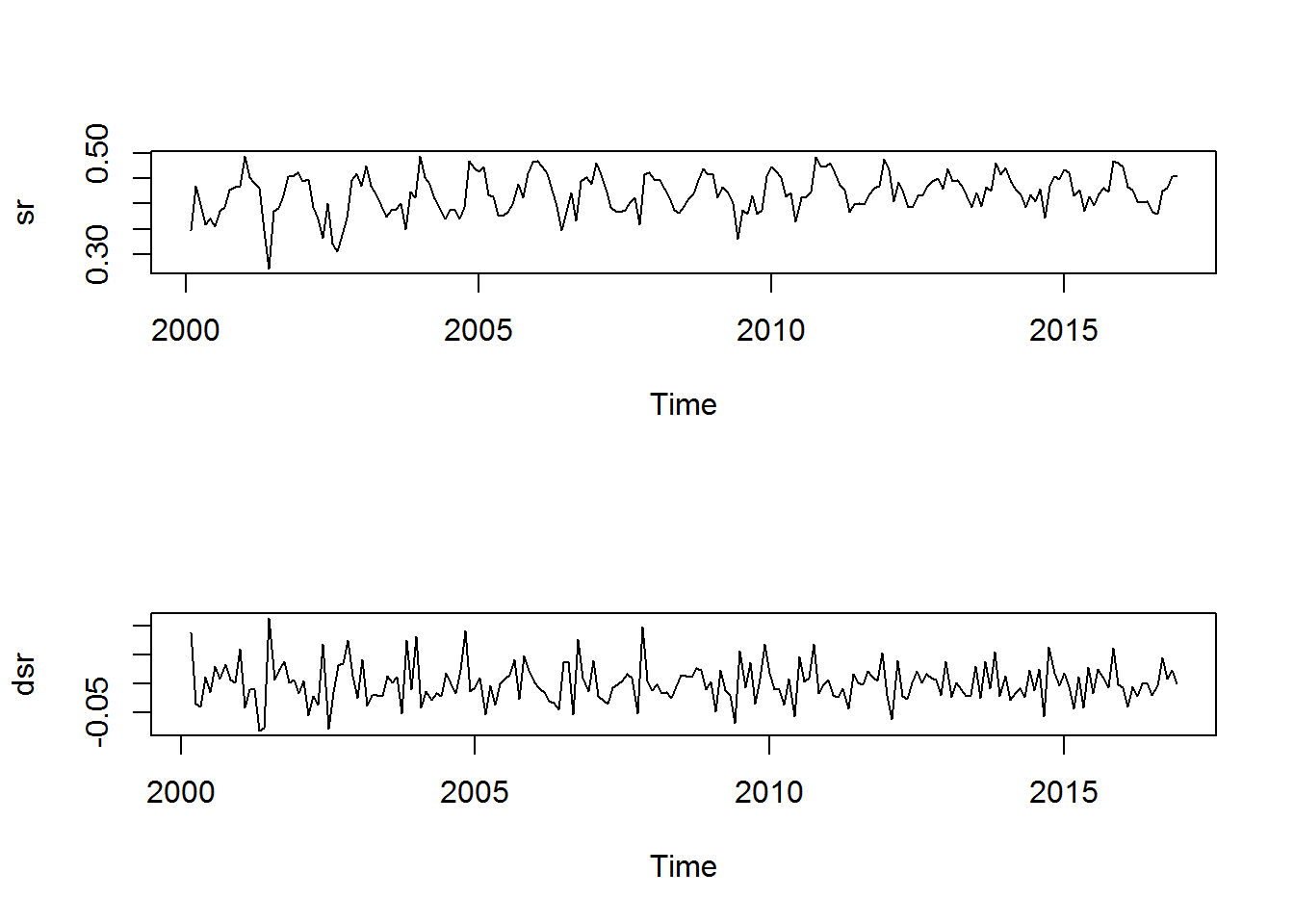
par(mfrow=c(1,1)) # Resetar los dos gráficos por panelAl hacer lo anterior, quitamos la tendencia y que quede lo más estacionaria posible. Ahora ensamblamos el modelo, pero antes, revisemos que nuestra serie sea estacionaria:
library(tseries)
adf.test(dsr) ## Warning in adf.test(dsr): p-value smaller than printed p-value##
## Augmented Dickey-Fuller Test
##
## data: dsr
## Dickey-Fuller = -9.3196, Lag order = 5, p-value = 0.01
## alternative hypothesis: stationaryNota: una serie no estacionaria es aquella en que sus parámetros estadísticos cambian a través del tiempo. La serie no oscila alrededor de un valor constante. Por el contrario, una serie estacionaria es aquella en que sus parámetros estadísticos NO cambian a través del tiempo. Los valores de la serie tienden a oscilar alrededor de una media constante y la variabilidad con respecto a esa media también permanece constante en el tiempo.
3.1.1 Residuos
par(mfrow=c(2,1))
acf(dsr)
pacf(dsr)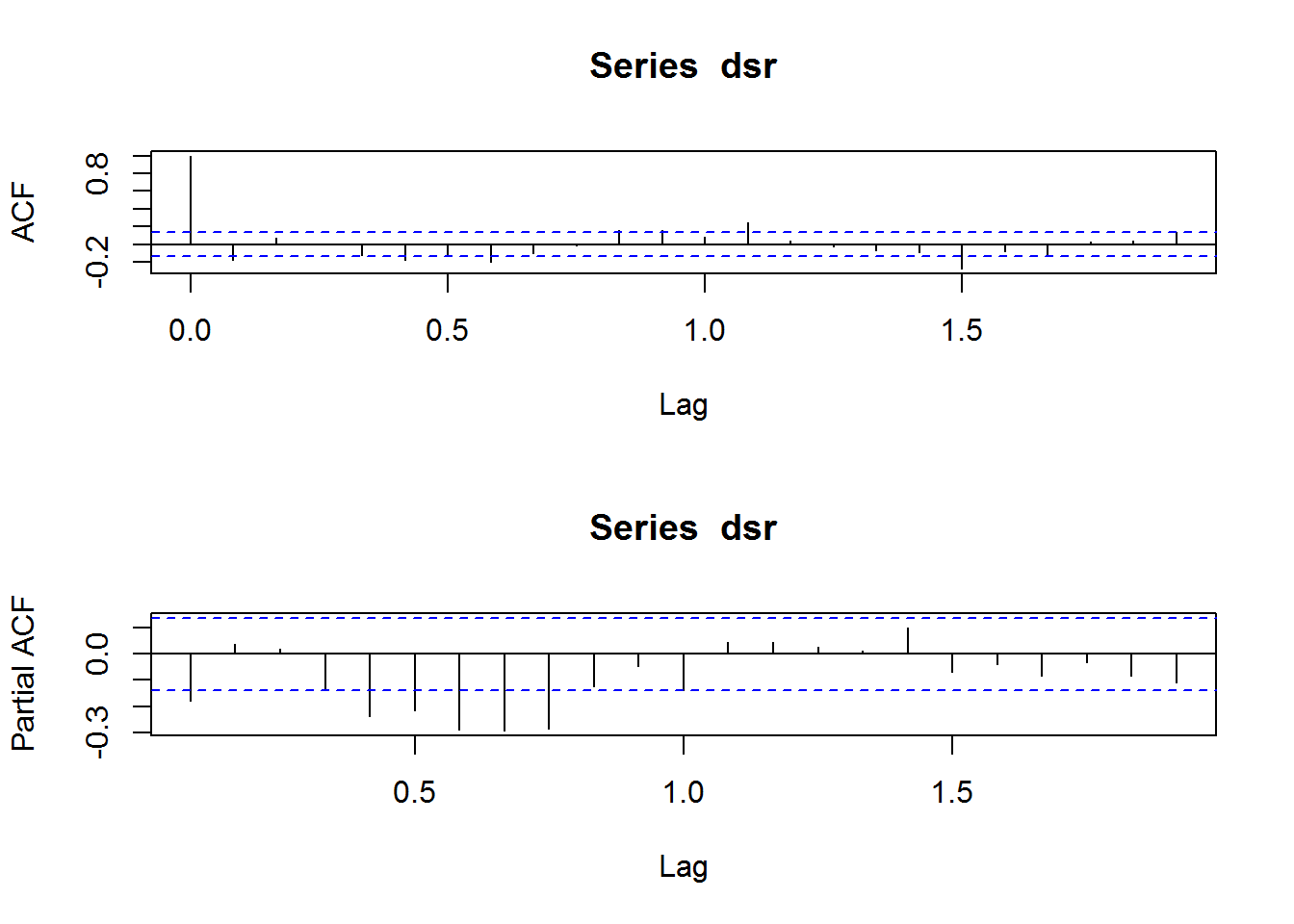
par(mfrow=c(1,1)) # Resetar los dos gráficos por panelPodemos aprovechar de revisar nuestras otras series:
acf(sm, na.action=na.pass)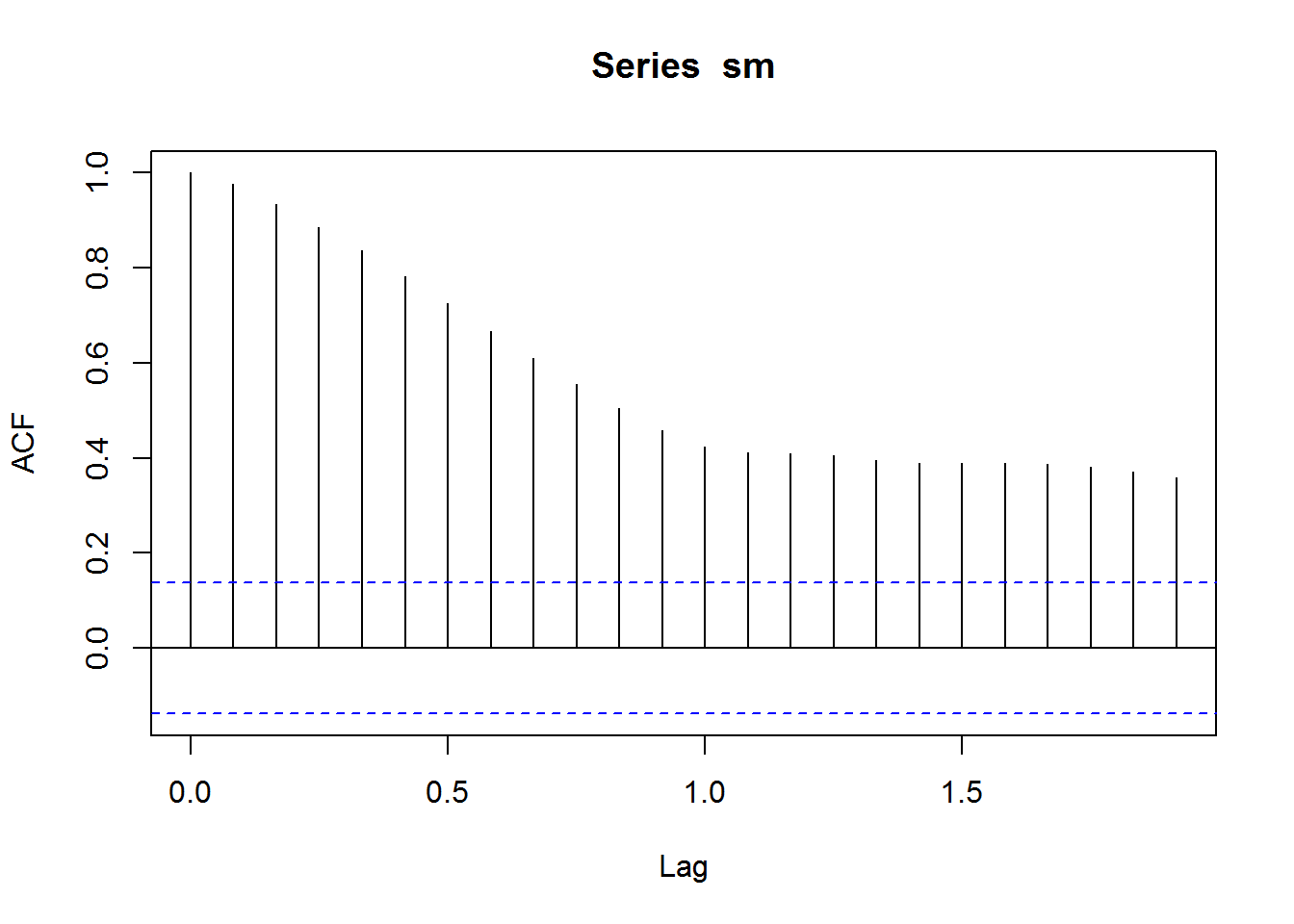
acf(season_sr, na.action=na.pass)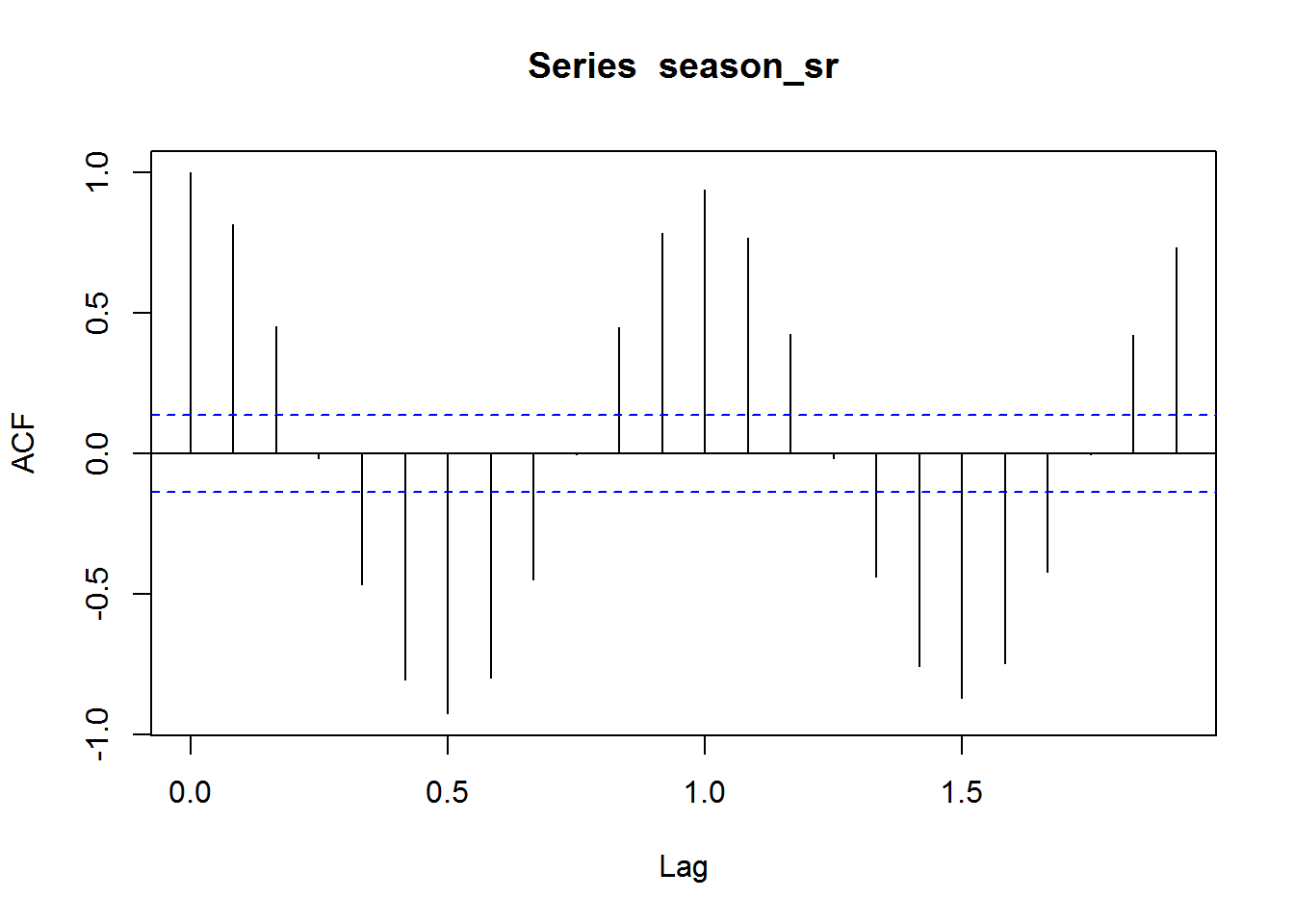
acf(noise, na.action=na.pass)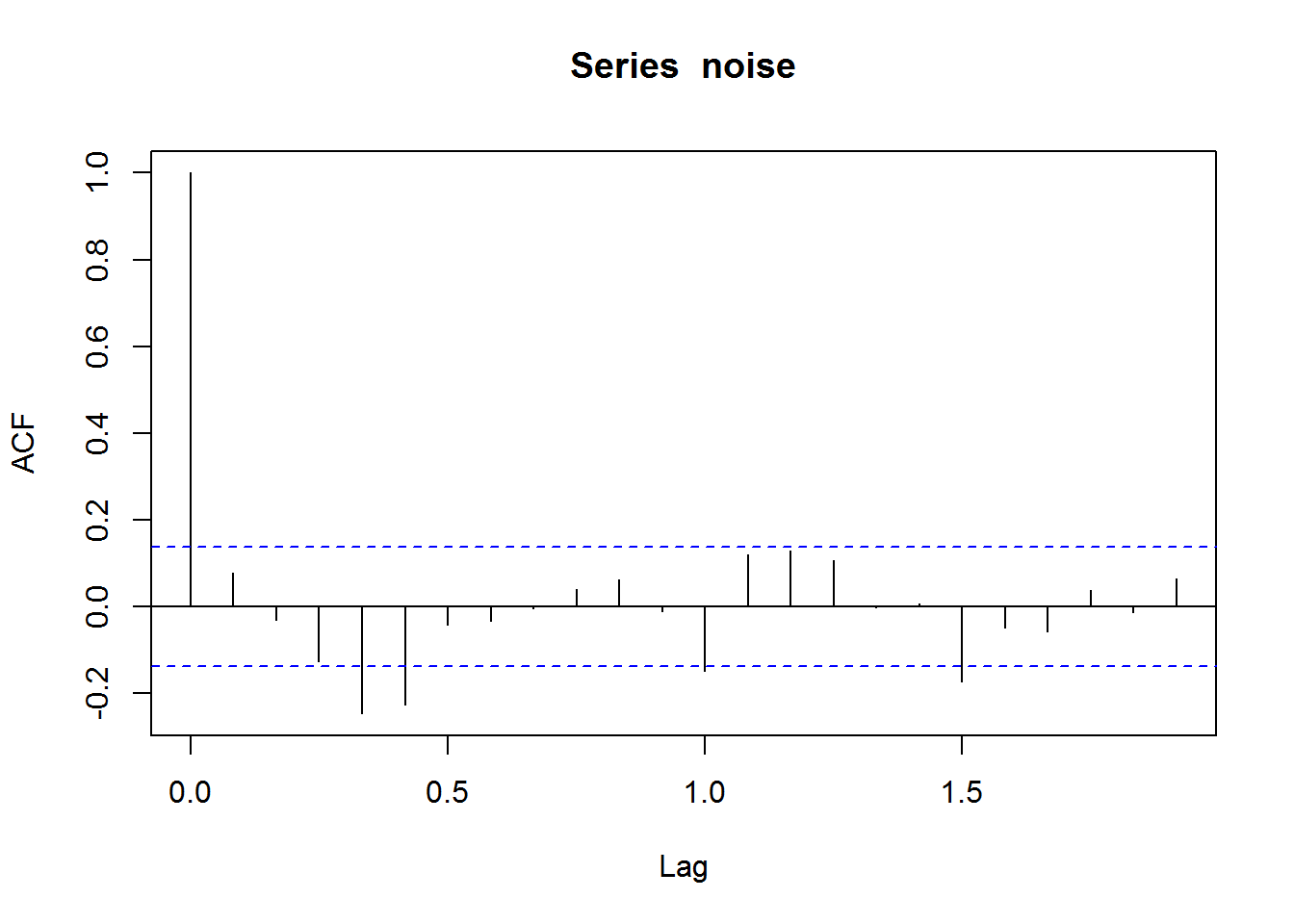
3.1.2 Ajustando ARIMA
Con la siguiente tabla y viendo los gráficos anteriores, podemos intentar definir que modelo utilizar
| Modelo | ACF | PACF |
|---|---|---|
| ARIMA(p, d, 0) | Tiende a 0 | Cero después de lag p |
| ARIMA(0, d, q) | Cero después de lag q | Tiende a 0 |
| ARIMA(p, d, q) | Tiende a 0 | Tiende a 0 |
Un poco complicado… no hay problema, R puede hacer el trabajo por nosotros con auto.arima. En caso de querer hacerlo manualmente, podemos usar la función base arima.
fit <- auto.arima(sr)
fit # A menor AIC, mejor## Series: sr
## ARIMA(2,1,0)(2,0,0)[12] with drift
##
## Coefficients:
## ar1 ar2 sar1 sar2 drift
## -0.4904 -0.1585 0.2131 0.4272 0.0006
## s.e. 0.0804 0.0766 0.0654 0.0701 0.0030
##
## sigma^2 estimated as 0.0009055: log likelihood=420.18
## AIC=-828.35 AICc=-827.92 BIC=-808.5tsdisplay(residuals(fit), lag.max=45, main='Model Residuals')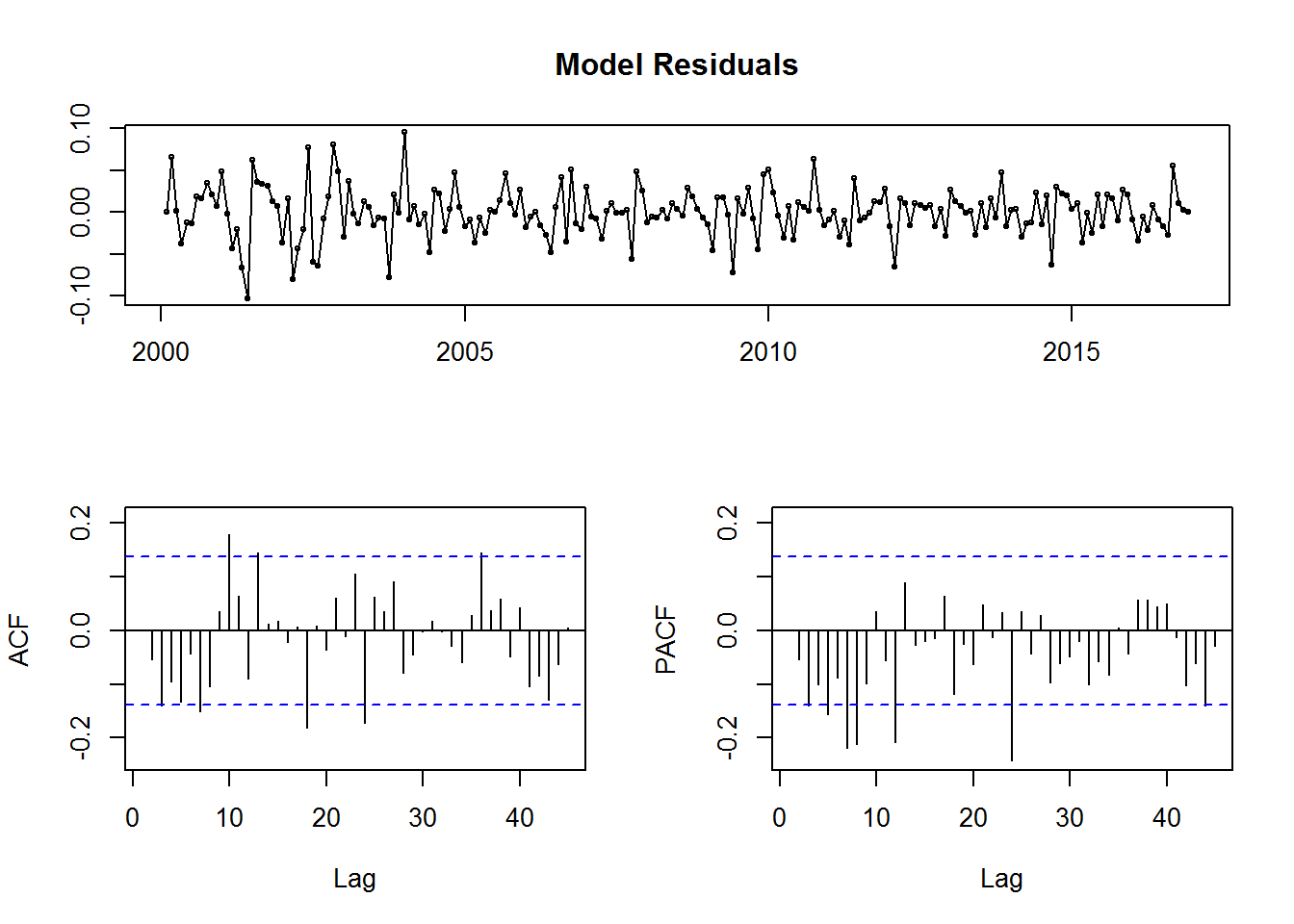
fit2 <- auto.arima(sr, seasonal=F)
fit2## Series: sr
## ARIMA(1,1,0)
##
## Coefficients:
## ar1
## -0.1864
## s.e. 0.0701
##
## sigma^2 estimated as 0.00112: log likelihood=400.12
## AIC=-796.23 AICc=-796.17 BIC=-789.61tsdisplay(residuals(fit2), lag.max=45, main='Model Residuals')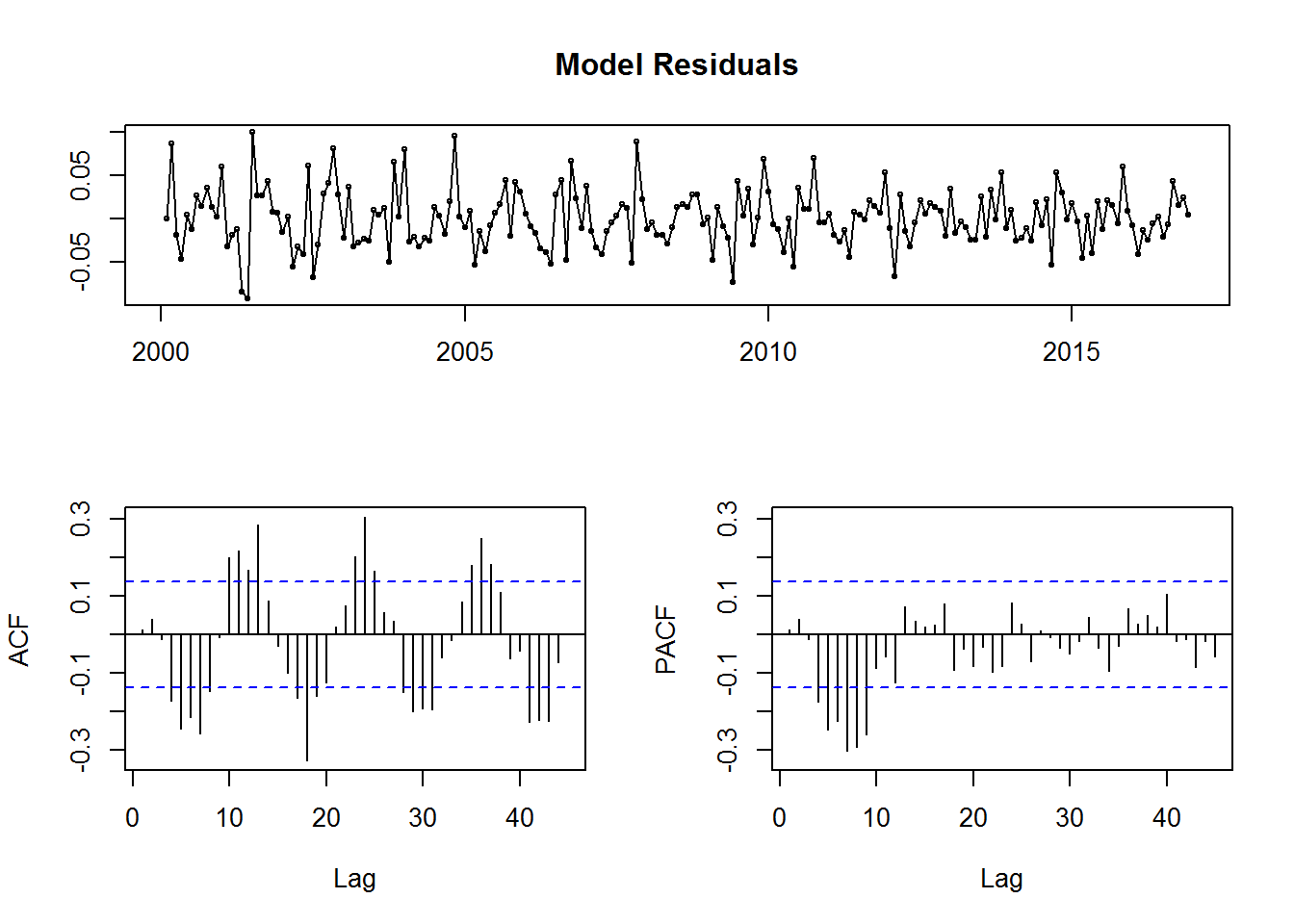
Al parecer no es tan bueno como esperábamos. Podemos intentar algo manual, pensando en que se ve algo de tendencia repetitiva de forma anual.
fit3 <- arima(sr, order=c(1,1,12))
fit3##
## Call:
## arima(x = sr, order = c(1, 1, 12))
##
## Coefficients:
## ar1 ma1 ma2 ma3 ma4 ma5 ma6
## -0.0074 -0.5492 -0.0948 -0.1428 -0.1936 -0.1367 -0.0414
## s.e. 1.0651 1.0627 0.6017 0.1305 0.1755 0.2239 0.1620
## ma7 ma8 ma9 ma10 ma11 ma12
## -0.1037 0.0749 0.1230 0.2117 0.0529 0.0136
## s.e. 0.1159 0.1364 0.1286 0.1633 0.2464 0.1086
##
## sigma^2 estimated as 0.0007433: log likelihood = 437.25, aic = -846.5tsdisplay(residuals(fit3), lag.max=45, main='Model Residuals')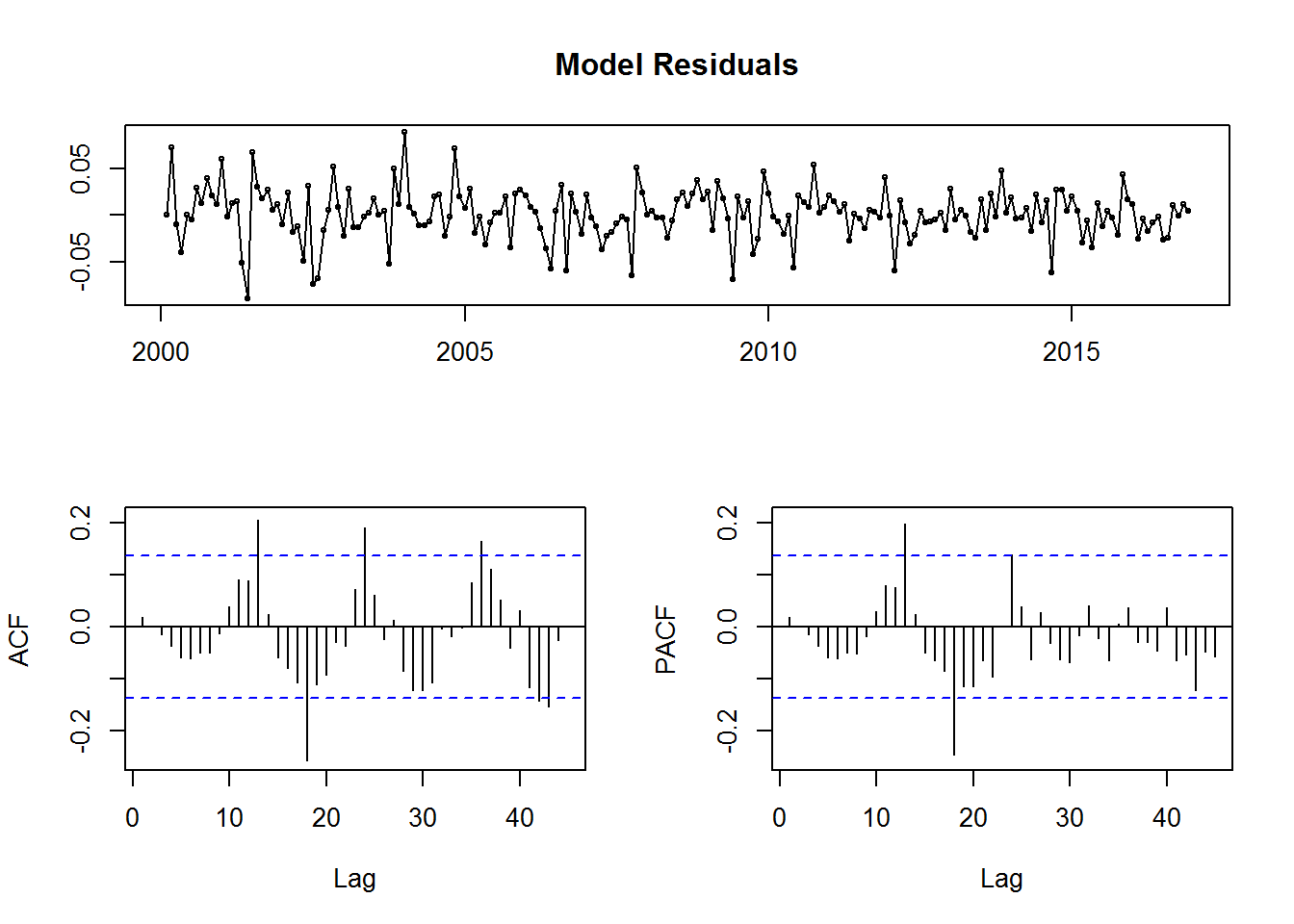
Un resultado un poco más estable, usemos este y comparemos luego entre fit3 y fit
Veamos otras pruebas para revisar, primero el modelo fit
qqnorm(fit$residuals)
qqline(fit$residuals, col="red")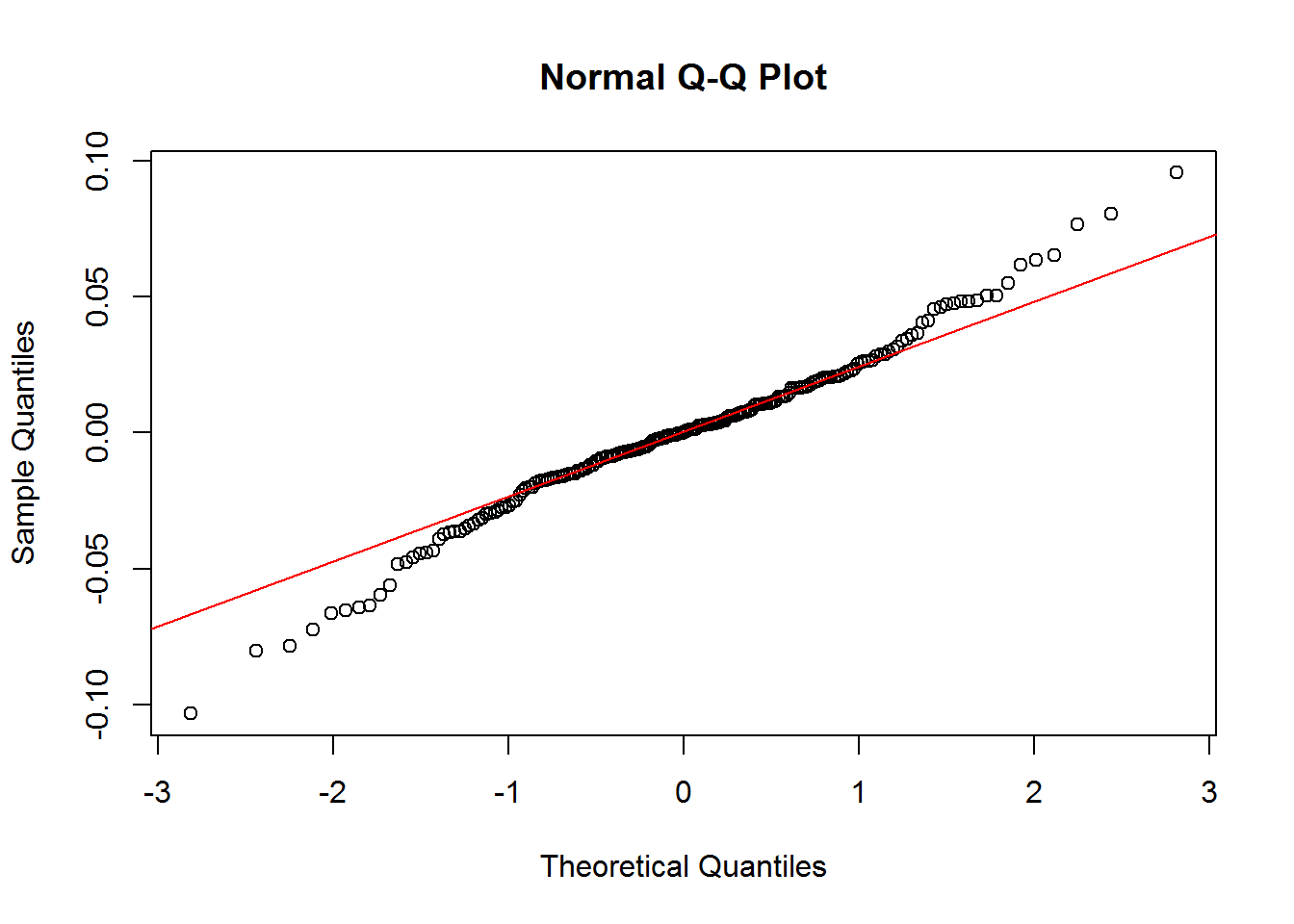
Box.test(fit$residuals, type="Ljung-Box")##
## Box-Ljung test
##
## data: fit$residuals
## X-squared = 0.0012169, df = 1, p-value = 0.9722Y luego fit3
qqnorm(fit3$residuals)
qqline(fit3$residuals, col="red")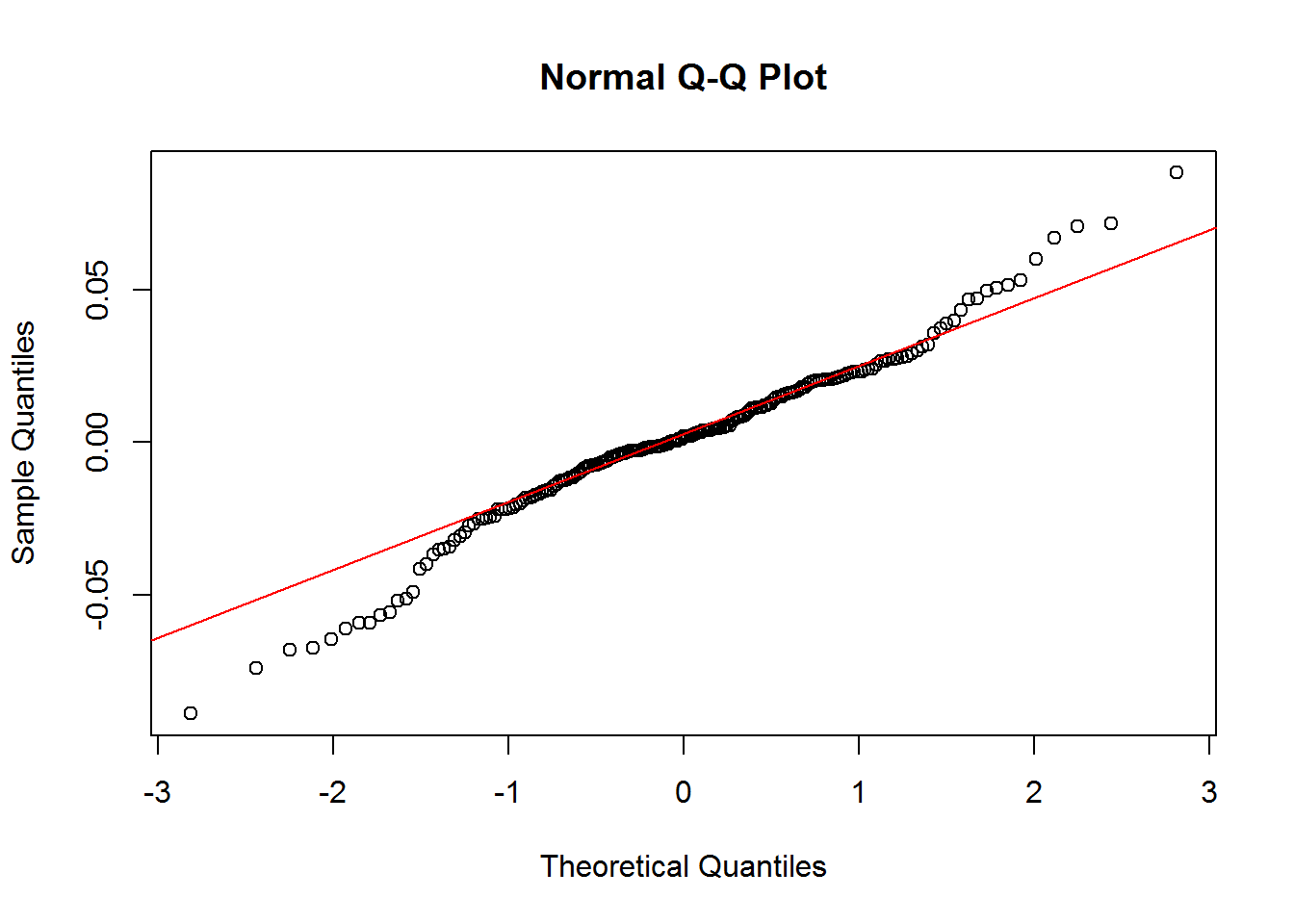
Box.test(fit3$residuals, type="Ljung-Box")##
## Box-Ljung test
##
## data: fit3$residuals
## X-squared = 0.072221, df = 1, p-value = 0.7881Entre ambos modelos, el mejor es fit3 puesto que todo indica que su autocorrelación es 0 (p no significativo con 0.7881). En los gráficos, lo ideal sería que los datos cayeran a lo largo de la línea. Los resultados no lucen mal, y eso indicaría que los datos tienen una distribución normal.
3.1.3 Predecir
f3 <- forecast(fit3, 12)
f3## Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
## Jan 2017 0.4491797 0.4140761 0.4842832 0.3954934 0.5028659
## Feb 2017 0.4446527 0.4061213 0.4831840 0.3857241 0.5035812
## Mar 2017 0.4394408 0.3988282 0.4800534 0.3773293 0.5015524
## Apr 2017 0.4301303 0.3887506 0.4715101 0.3668455 0.4934152
## May 2017 0.4211803 0.3797859 0.4625747 0.3578730 0.4844876
## Jun 2017 0.4144519 0.3729080 0.4559958 0.3509159 0.4779878
## Jul 2017 0.4153567 0.3735074 0.4572060 0.3513538 0.4793596
## Aug 2017 0.4170994 0.3743357 0.4598630 0.3516980 0.4825007
## Sep 2017 0.4200797 0.3768555 0.4633040 0.3539739 0.4861856
## Oct 2017 0.4214941 0.3782176 0.4647707 0.3553084 0.4876799
## Nov 2017 0.4218489 0.3782632 0.4654345 0.3551904 0.4885073
## Dec 2017 0.4219005 0.3777623 0.4660386 0.3543970 0.4894039plot(f3)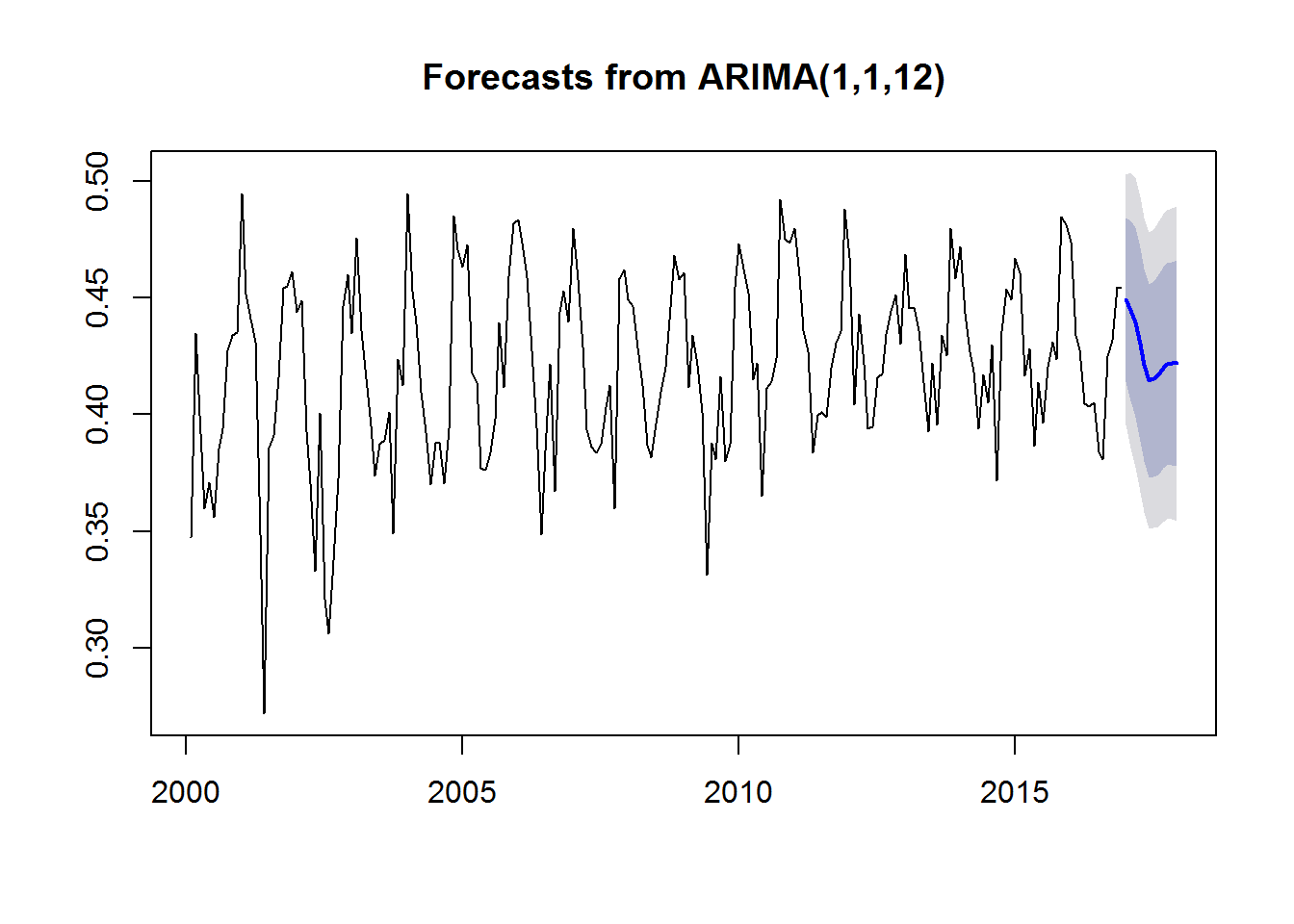
3.1.4 Sigan probando
Pruebe los resultados usando el modelo fit (el que auto.arima encontró automáticamente)
Posteriormente, prueben con el conjunto de datos Nile.
4 Tarea
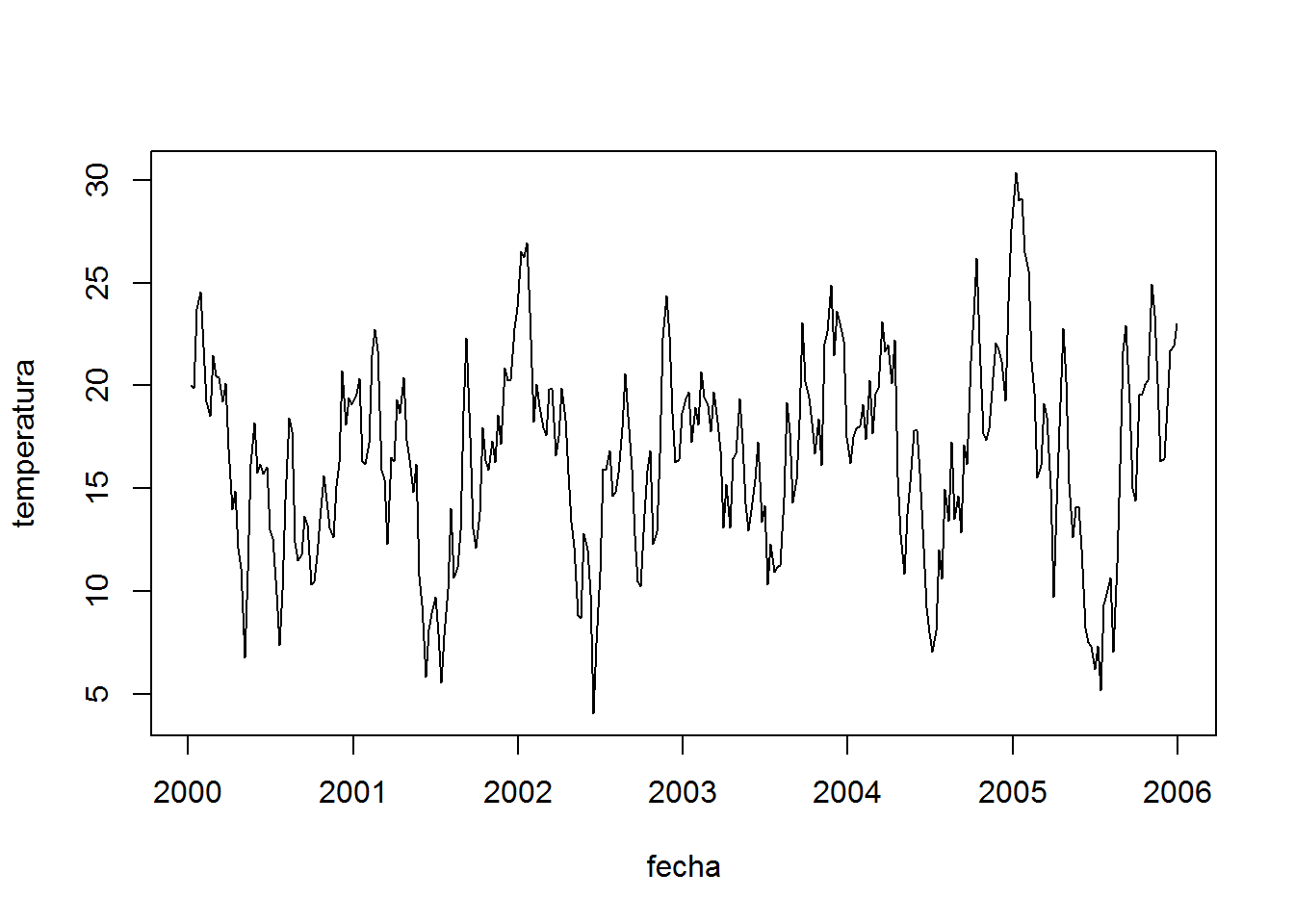
Los datos están acá.
- ¿Pueden descomponer y analizar la siguiente serie de tiempo generada?
- ¿Puede ajustar un modelo ARIMA?
- ¿Puede generar su propia serie de tiempo?