Exploratoria
Álvaro Paredes y Carlos Lara
20 Julio de 2017
1 Cargar datos de ejemplo
Primero, descarga estos datos a tu computador (idealmente a algún lugar de fácil acceso). Copia la ruta donde has descargado los datos y ejecuta el siguiente comando:
setwd("RUTA AL ARCHIVO")La ruta al archivo debe ser completa; por ejempo, si está en el escritorio, debería ser algo como "C:/Usuario/Escritorio/curso_R/". Hay que prestar atención a las barras diagonales (“slash”). Estas deben ser hacia la derecha como en el ejemplo, o dobles hacia la izquierda: "C:\\Usuario\\Escritorio\\curso_R\\". De no ser así, no funcionará adecuadamente. Con este comando le decimos a R que ese será nuestro directorio de trabajo y cualquier archivo que llamemos o guardemos, si no específicamos la dirección completa, se guardará ahí.
df <- read.csv("EVI.csv", stringsAsFactors=F)
head(df)## date EVI
## 1 2000-02-15 0.3474081
## 2 2000-03-15 0.4349093
## 3 2000-04-15 0.3997135
## 4 2000-05-15 0.3596721
## 5 2000-06-15 0.3709763
## 6 2000-07-15 0.3561040head(df, 10)## date EVI
## 1 2000-02-15 0.3474081
## 2 2000-03-15 0.4349093
## 3 2000-04-15 0.3997135
## 4 2000-05-15 0.3596721
## 5 2000-06-15 0.3709763
## 6 2000-07-15 0.3561040
## 7 2000-08-15 0.3853246
## 8 2000-09-15 0.3937942
## 9 2000-10-15 0.4273154
## 10 2000-11-15 0.4339750tail(df, 10)## date EVI
## 194 2016-03-15 0.4276451
## 195 2016-04-15 0.4045628
## 196 2016-05-15 0.4034853
## 197 2016-06-15 0.4052441
## 198 2016-07-15 0.3840768
## 199 2016-08-15 0.3807446
## 200 2016-09-15 0.4249608
## 201 2016-10-15 0.4320328
## 202 2016-11-15 0.4545806
## 203 2016-12-15 0.4541745str(df) # Nos mostrará la estructura## 'data.frame': 203 obs. of 2 variables:
## $ date: chr "2000-02-15" "2000-03-15" "2000-04-15" "2000-05-15" ...
## $ EVI : num 0.347 0.435 0.4 0.36 0.371 ...class(df) # ¿Qué clase de objeto es?## [1] "data.frame"typeof(df) # ¿Qué tipo de objeto es?## [1] "list"Para cargar los datos utilizamos read.csv, que es una forma simplificada de read.table (?read.table para ver más información). Hay una variante para archivos csv en “formato español”, que es read.csv2. Todas estas funciones tienen los mismos parámetros de configuración (que son muchos), pero los principales:
header: Si es verdadero, se asume que la primera fila son los nombre de cada columna.sep: El caracter que demarca la separación entre columnas. Normalmente es ‘,’ o ‘;’.dec: El caracter que indica el separador decimal es ‘.’ o ‘,’.
En resumen read.csv("EVI.csv"") es lo mismo que read.table("EVI.csv", header=TRUE, sep=",", dec=".")
2 Explorando los datos
Una vez cargados los datos, podemos obtener algunas estadísticas rápidas para hacernos una idea de lo que tenemos al frente:
summary(df) # Resumen de estadísticas## date EVI
## Length:203 Min. :0.2717
## Class :character 1st Qu.:0.3938
## Mode :character Median :0.4217
## Mean :0.4201
## 3rd Qu.:0.4492
## Max. :0.4946min(df$EVI, na.rm=T) # El valor mínimo de la serie## [1] 0.2717251max(df$EVI, na.rm=T) # El valor máximo## [1] 0.4945951range(df$EVI, na.rm=T) # El valor mínimo y máximo## [1] 0.2717251 0.4945951mean(df$EVI, na.rm=T) # La media## [1] 0.4201368median(df$EVI, na.rm=T) # La mediana## [1] 0.4217237sd(df$EVI, na.rm=T) # La desviación estándar## [1] 0.03869092var(df$EVI, na.rm=T) # La varianza## [1] 0.001496987quantile(df$EVI) # La distribución por quintiles## 0% 25% 50% 75% 100%
## 0.2717251 0.3938126 0.4217237 0.4491904 0.4945951quantile(df$EVI, seq(0.1, 1, by=0.1)) # La distribución por deciles## 10% 20% 30% 40% 50% 60% 70%
## 0.3727624 0.3876094 0.3987207 0.4126836 0.4217237 0.4312171 0.4436416
## 80% 90% 100%
## 0.4546812 0.4702500 0.4945951Un data.frame como este, puede ser manipulado de varias maneras:
min(df$EVI) == min(df[, 2])## [1] TRUEmin(df$EVI) == min(df[, "EVI"])## [1] TRUEmin(df$EVI) == min(df[, c("EVI")]) # Para cuando se quiera extraer más de una columna. Lo mismo aplica con la posición.## [1] TRUEY un gráfico simple que nos permitirá ver nuestros datos:
plot(df$EVI) # Gráfico de puntos
plot(df$EVI, type="l", ylab="EVI", main="Gráfico 1") # Gráfico de líneas 
hist(df$EVI) # Histograma
hist(df$EVI, breaks=c(.25, .3, .35, .4, .45, .5)) # Histograma con quiebres definidos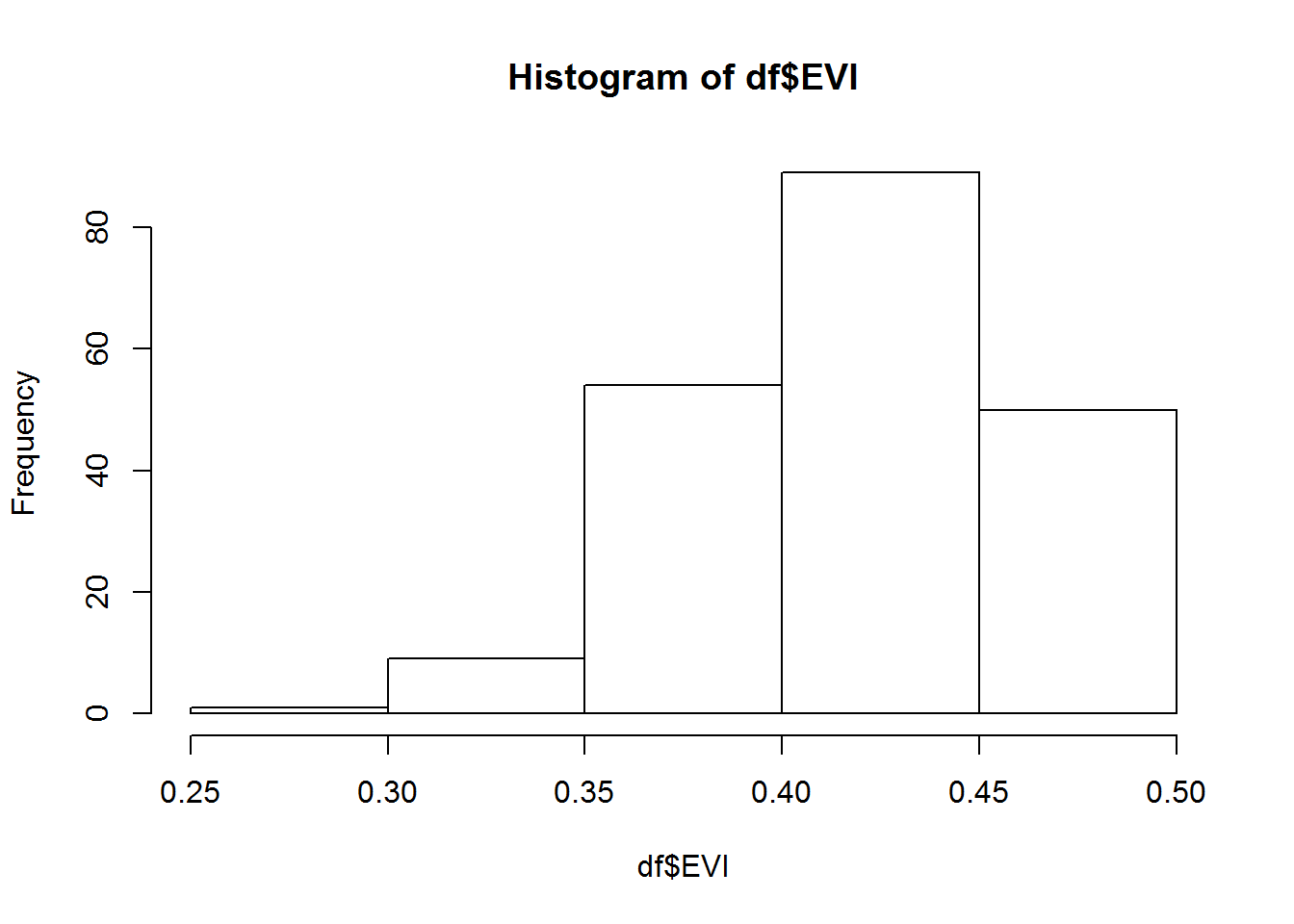
De a poco iremos viendo como ir personalizando y mejorando nuestros gráficos. Con esto ya es suficiente para hacerse una idea de como vienen los datos que se tengan que procesar.
3 Fechas y secuencias
En R existe un tipo para fecha date, que facilita el manejo del tiempo en nuestros datos. Cuántos días, semanas, meses o años han pasado entre una fecha y otra, son muy fáciles de obtener si los datos de fecha están en ese formato.
Recordando nuestros datos en df, sabemos que tenemos dos columnas, una llamada date de texto y la otra EVI de números decimales (str(df) les ayudará a confirmar esto). La columna date claramente tiene una estructura de fechas, que actualmente R no está reconociendo como tal.
Transformaremos la columna date a fecha con el siguiente comando:
df$date <- as.Date(df$date, "%Y-%m-%d")
str(df) # Para comprobar el cambio## 'data.frame': 203 obs. of 2 variables:
## $ date: Date, format: "2000-02-15" "2000-03-15" ...
## $ EVI : num 0.347 0.435 0.4 0.36 0.371 ...summary(df)## date EVI
## Min. :2000-02-15 Min. :0.2717
## 1st Qu.:2004-04-30 1st Qu.:0.3938
## Median :2008-07-15 Median :0.4217
## Mean :2008-07-15 Mean :0.4201
## 3rd Qu.:2012-09-30 3rd Qu.:0.4492
## Max. :2016-12-15 Max. :0.4946En vez de haber sobreescrito la columna, podríamos haber creado con otro nombre. Por ejemplo, con df$fecha <- as.Date(df$date, "%Y-%m-%d") hubieramos guardado en una nueva columna llamada fecha la información transformada, conservando la original (terminando con 3 columnas en vez de dos).
Como se aprecia al transformar los datos, se usa una cadena de texto para informar en que formato se encuentra dicha fecha, para que el programa la pueda reconocer. Son muchas las formas en que se puede dar formato a una fecha, ?strftime les dará un amplio listado de ellas, pero veremos algunas a continuación.
df$doy <- as.numeric(strftime(df$date, "%j")) # Día del año. Como devuelve un texto, lo transformamos de inmediato a número.
df$month <- as.numeric(strftime(df$date, "%m"))
df$year <- as.numeric(strftime(df$date, "%Y"))Y obviamente, podemos volver atrás y de paso ver otro comando útil: paste y paste0 que equivalente a concatenar en excel, que corresponde a pegar dos o más variables en una cadena de texto. Primero armemos una cadena de texto que contenga el día del año y el año, y luego lo transformamos a fecha nuevamente, para recomponer la columna original date.
head(paste0(df$doy, "-", df$year))## [1] "46-2000" "75-2000" "106-2000" "136-2000" "167-2000" "197-2000"head(as.Date(paste0(df$doy, "-", df$year), "%j-%Y"))## [1] "2000-02-15" "2000-03-15" "2000-04-15" "2000-05-15" "2000-06-15"
## [6] "2000-07-15"# Finalmente, veamos si el resultado es igual que el original:
all(as.Date(paste0(df$doy, "-", df$year), "%j-%Y") == df$date)## [1] TRUEHasta ahora, deberíamos tener un data.frame con 5 columnas:
colnames(df)## [1] "date" "EVI" "doy" "month" "year"Podemos obtener un subset de nuestros datos y gráficarlos frente a la serie completa, para ver la diferencia:
plot(df$date, df$EVI, type="l")
lines(df$date[df$year >= 2010], df$EVI[df$year >= 2010], col="red") # Todos nuestros valores de EVI desde el 2010 en adelante
lines(df$date[df$year >= 2005], df$EVI[df$year >= 2005] - 0.05, col="blue") # Ídem al anterior, pero desde el 2005 y le restamos 0.05 para que se separe del resto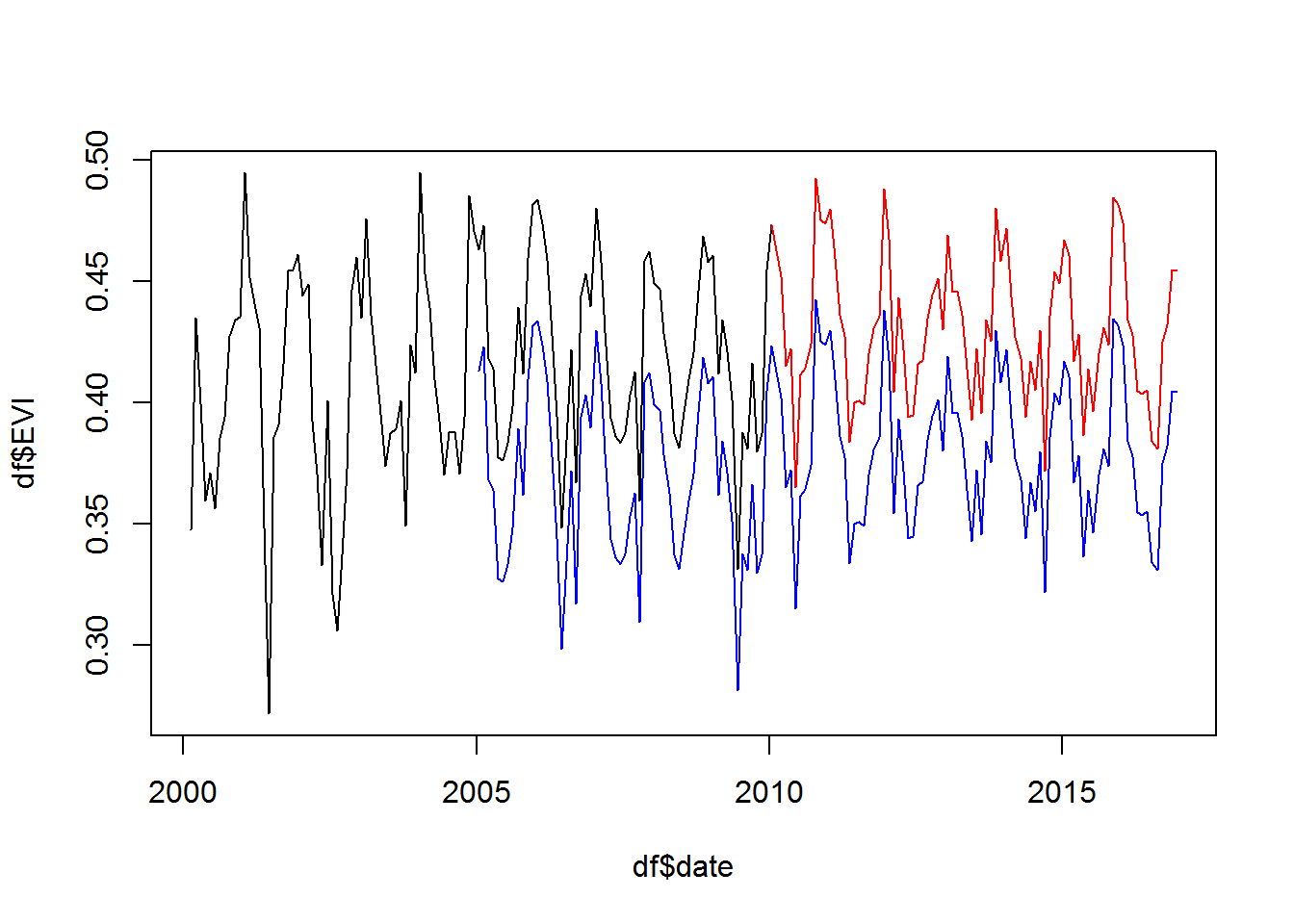
Podemos hacer un rápido recuento de cuántos meses o años de datos tenemos disponibles en total; incluso de cuántos registros de mes por año.
table(df$month) # Cantidad de registros por mes##
## 1 2 3 4 5 6 7 8 9 10 11 12
## 16 17 17 17 17 17 17 17 17 17 17 17table(df$year) # Cantidad de registros por año##
## 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014
## 11 12 12 12 12 12 12 12 12 12 12 12 12 12 12
## 2015 2016
## 12 12table(df$year, df$month) # Cantidad de registros por año y mes##
## 1 2 3 4 5 6 7 8 9 10 11 12
## 2000 0 1 1 1 1 1 1 1 1 1 1 1
## 2001 1 1 1 1 1 1 1 1 1 1 1 1
## 2002 1 1 1 1 1 1 1 1 1 1 1 1
## 2003 1 1 1 1 1 1 1 1 1 1 1 1
## 2004 1 1 1 1 1 1 1 1 1 1 1 1
## 2005 1 1 1 1 1 1 1 1 1 1 1 1
## 2006 1 1 1 1 1 1 1 1 1 1 1 1
## 2007 1 1 1 1 1 1 1 1 1 1 1 1
## 2008 1 1 1 1 1 1 1 1 1 1 1 1
## 2009 1 1 1 1 1 1 1 1 1 1 1 1
## 2010 1 1 1 1 1 1 1 1 1 1 1 1
## 2011 1 1 1 1 1 1 1 1 1 1 1 1
## 2012 1 1 1 1 1 1 1 1 1 1 1 1
## 2013 1 1 1 1 1 1 1 1 1 1 1 1
## 2014 1 1 1 1 1 1 1 1 1 1 1 1
## 2015 1 1 1 1 1 1 1 1 1 1 1 1
## 2016 1 1 1 1 1 1 1 1 1 1 1 1Otro comando útil es el que nos permita obtener los valores únicos. Supongamos que se necesita saber en que días del año hay datos, independientemente.
unique(df$doy)## [1] 46 75 106 136 167 197 228 259 289 320 350 15 74 105 135 166 196
## [18] 227 258 288 319 349sort(unique(df$doy)) # días únicos ordenados esta vez## [1] 15 46 74 75 105 106 135 136 166 167 196 197 227 228 258 259 288
## [18] 289 319 320 349 350Y por último las secuencias (muy útiles también)
mi_seq <- seq(0, 1000, by=0.2)
head(mi_seq)## [1] 0.0 0.2 0.4 0.6 0.8 1.0tail(mi_seq)## [1] 999.0 999.2 999.4 999.6 999.8 1000.0length(mi_seq)## [1] 5001Y ciertamente podríamos querer ordenarlas de manera inversa:
head(sort(mi_seq, decreasing=T))## [1] 1000.0 999.8 999.6 999.4 999.2 999.04 Valores perdidos
En algunas ocasiones, al tratar con una serie de datos, podemos tener registros sin valores. Dependiendo de los objetivos que tengamos, podríamos querer eliminar estos registros y quedarnos sólo con observaciones válidas. En R hay diferentes funciones (como mean, max, min, entre otras), que si no incluye un parámetro que excluya dichos valores ausentes, el resultado será un valor ausente NA (a pesar de contener registros válidos).
mi_seq2 <- mi_seq # Primero hacemos una copia y luego asignamos valores NA a la copia
mi_seq2[sample(1:length(mi_seq2), 20)] <- NAEn la línea anterior, lo que se hizo fue introducir 20 valores NA en la secuencia completa mi_seq2 de manera aleatoria. sample toma una muestra aleatoria de los valores proporcionados (en este caso de 1 hasta el número de registros de mi_seq2) de tamaño n, que en este caso fue de 20. Esos 20 seleccionados, corresponden a las posiciones dentro del vector que serán reemplazadas con NA. Pueden especificar si la muestra es con reemplazo y asignar probabilidades también (?sample).
Luego podemos lidiar con estos valores NA de dos formas:
mi_seq3 <- na.omit(mi_seq2) # Removiéndolos
length(mi_seq3) # comprobando que la cantidad de elementos es menor## [1] 4981which(is.na(mi_seq2)) # ¿en que posiciones están esos valores NA?## [1] 205 273 802 1132 1727 2081 2155 2474 2484 2734 3125 3632 3753 3795
## [15] 4106 4153 4540 4557 4590 4798library(forecast)
mi_seq_int <- na.interp(mi_seq2) # Interpolando¿Y qué tal resultó esta interpolación?
mi_seq[which(is.na(mi_seq2))] == mi_seq_int[which(is.na(mi_seq2))]## [1] FALSE TRUE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
## [12] TRUE TRUE FALSE TRUE TRUE FALSE TRUE FALSE TRUE# Quizás de esta forma se pueden comparar mejor
cbind(mi_seq[which(is.na(mi_seq2))], mi_seq_int[which(is.na(mi_seq2))])## [,1] [,2]
## [1,] 40.8 40.8
## [2,] 54.4 54.4
## [3,] 160.2 160.2
## [4,] 226.2 226.2
## [5,] 345.2 345.2
## [6,] 416.0 416.0
## [7,] 430.8 430.8
## [8,] 494.6 494.6
## [9,] 496.6 496.6
## [10,] 546.6 546.6
## [11,] 624.8 624.8
## [12,] 726.2 726.2
## [13,] 750.4 750.4
## [14,] 758.8 758.8
## [15,] 821.0 821.0
## [16,] 830.4 830.4
## [17,] 907.8 907.8
## [18,] 911.2 911.2
## [19,] 917.8 917.8
## [20,] 959.4 959.4# O quizás así:
mi_seq[which(is.na(mi_seq2))] - mi_seq_int[which(is.na(mi_seq2))]## [1] 7.105427e-15 0.000000e+00 2.842171e-14 2.842171e-14 0.000000e+00
## [6] 0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00
## [11] 1.136868e-13 0.000000e+00 0.000000e+00 1.136868e-13 0.000000e+00
## [16] 0.000000e+00 1.136868e-13 0.000000e+00 1.136868e-13 0.000000e+005 Secuencias aleatorias
A veces es útil poder generar datos con alguna distribución aleatoria (semi-aleatoria en realidad, debido a las características intrínsecas de los computadores). Hay una gran cantidad de distribuciones disponibles para la generación de números, pero las más populares son runif y rnorm, para números aleatorios con distribución uniforme y con distribución normal respectivamente. ?distributions muestra un listado con los tipos de distribución que se pueden ir generando.
En general, cada distribución posee cuatro subfunciones. Como base, usaremos la distribución normal:
dnorm: Equivalente a d + norm, entrega la probabilidad de obtener un número x, dada una distribución de media \(\mu\) y de desviación estándar \(\sigma\) (por defecto, corresponden a 0 y 1 respectivamente).pnorm: Equivalente a p + norm, entrega la probabilidad acumulada de obtener un número x, dada una distribución de media \(\mu\) y de desviación estándar \(\sigma\).qnorm: Equivalente a q + norm, entrega el valor que corresponde a la probabilidad específicada x, dada una distribución de media \(\mu\) y de desviación estándar \(\sigma\).rnorm: Equivalente a r + norm, genera números aleatorios con distribución de media \(\mu\) y de desviación estándar \(\sigma\).
Podemos probar cada una:
sq1 <- seq(-3, 3, by=0.1) # Primero generamos la secuencia base.
plot(dnorm(sq1)) # Grafica la probabilidad de obtener los números de la secuencia.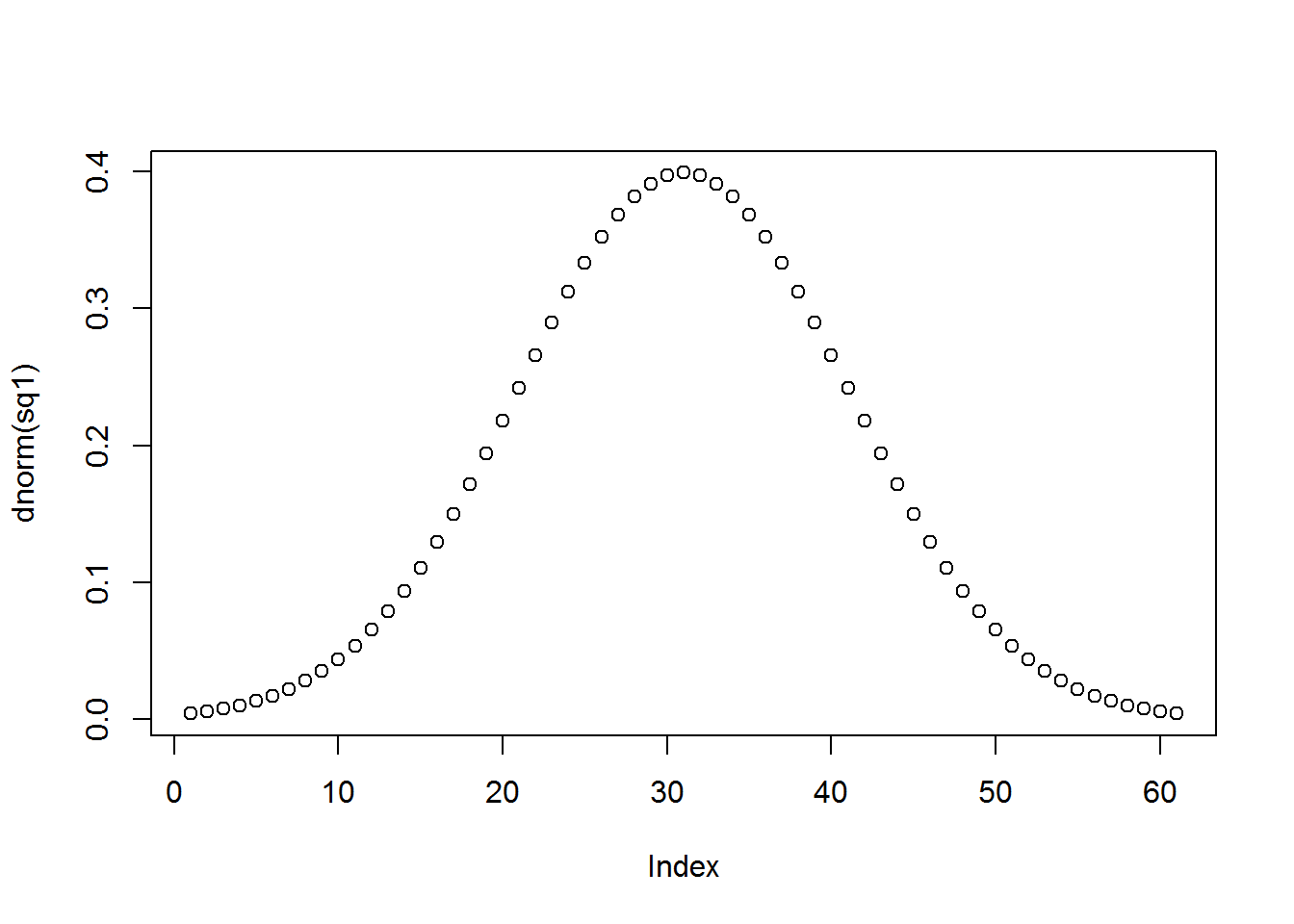
plot(pnorm(sq1)) # Grafica la probabilidad acumulada de obtener los números de la secuencia.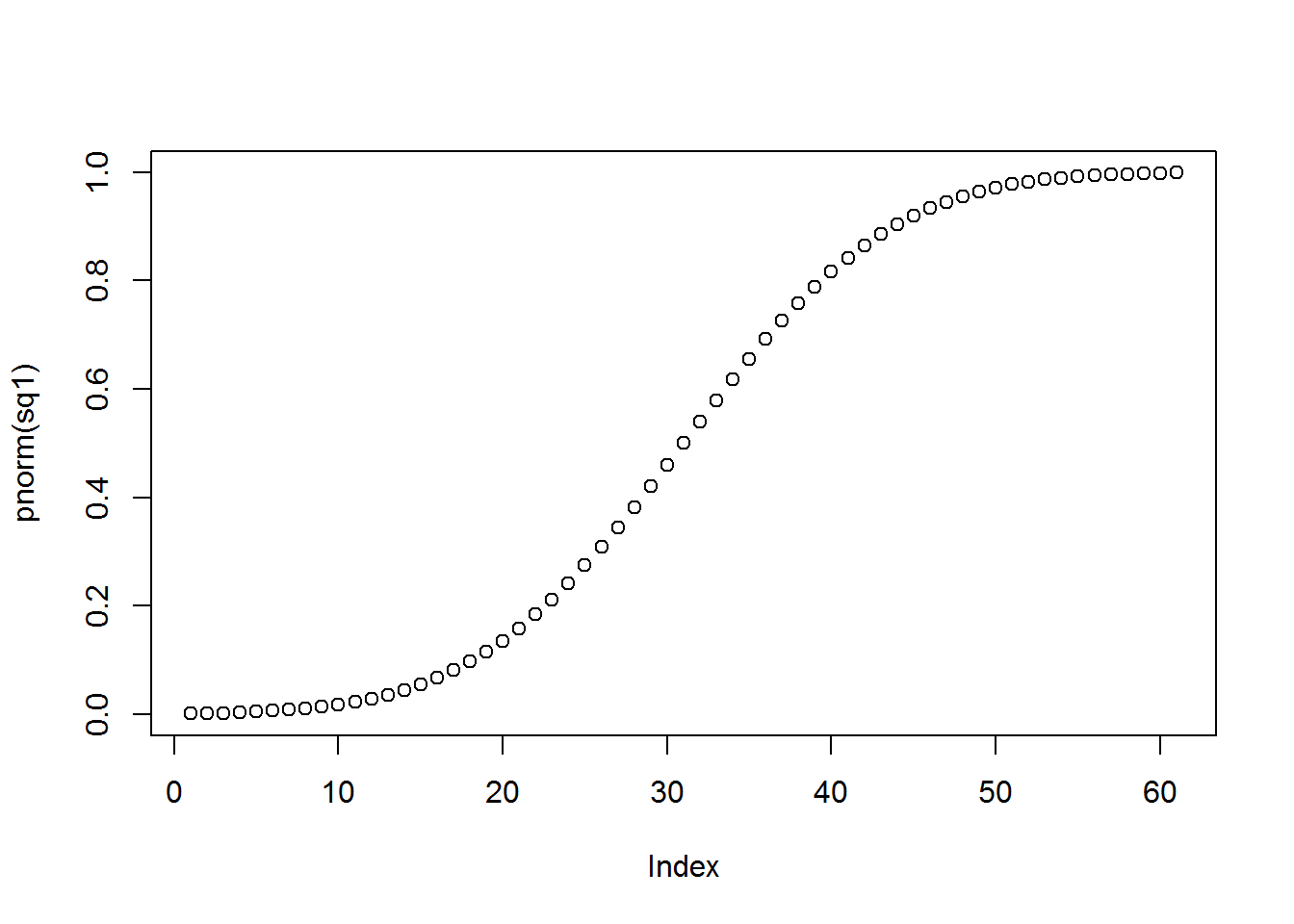
sq2 <- 1:length(sq1)/(length(sq1) + 1) # Cambiar secuencia, se necesitan probabilidades ahora
plot(qnorm(sq2))
sq3 <- rnorm(length(sq1)) # Generar n números al azar con distribución normal
plot(sq3)
plot(sort(sq3))
Y la distribución uniforme:
plot(runif(length(sq1)))
6 Gráficos
Ya hemos visto algunos gráficos simples, es hora de comenzar a personalizarlos un poco, según las necesidades de cada uno. Puntos y líneas son gráficos similares, salvo por un par de parámetros. Volvamos a gráficar el EVI a través de la serie temporal.
6.1 Líneas
par(bg = "grey90")
plot(df$date, df$EVI, type="b", xlab="Year", ylab="EVI", main="The best plot!",
bty="n", xaxt="n", yaxt="n", col="red", lwd=2, family="mono", lty=1, pch=16, cex=.8)
axis(2, las=2, cex.axis=.8)
axis(1, las=1, cex.axis=.8,
at=df$date[0:(length(unique(df$year)) - 1) * 12 + 1], labels=sort(unique(df$year)))
Hay muchas cosas que podemos cambiar, pero haremos un par de cambios simples
par(bg = "grey90")
plot(df$date, df$EVI, type="l", xlab="Year", ylab="EVI", main="The best plot!",
bty="n", xaxt="n", yaxt="n", col="blue", lwd=2, family="mono", lty=1)
axis(2, las=2, cex.axis=.8)
axis(1, las=1, cex.axis=.8,
at=df$date[0:(length(unique(df$year)) - 1) * 12 + 1], labels=sort(unique(df$year)))
legend("bottomright", legend="EVI", col="blue", lty=1)
6.2 Puntos
Con puntos se pueden hacer algunas cosas más:
par(bg = "grey70")
plot(df$date, df$EVI, type="p", xlab="Year", ylab="EVI", main="The second best plot!",
bty="n", xaxt="n", yaxt="n", col=terrain.colors(length(unique(df$year)))[as.numeric(as.factor(df$year)) + 1],
family="mono", pch=16, cex=.8)
axis(2, las=2, cex.axis=.8)
axis(1, las=1, cex.axis=.8,
at=df$date[0:(length(unique(df$year)) - 1) * 12 + 1], labels=sort(unique(df$year)))
Con leyenda:
par(mar=c(5.1, 4.1, 4.1, 8.1), xpd=TRUE, bg="grey70")
plot(df$date, df$EVI, type="p", xlab="Year", ylab="EVI", main="The third best plot?",
bty="n", xaxt="n", yaxt="n", col=topo.colors(length(unique(df$year)))[as.numeric(as.factor(df$year)) + 1],
family="mono", pch=16, cex=.8)
axis(2, las=2, cex.axis=.8)
axis(1, las=1, cex.axis=.8,
at=df$date[0:(length(unique(df$year)) - 1) * 12 + 1], labels=sort(unique(df$year)))
legend("bottomright", legend=unique(df$year), col=topo.colors(length(unique(df$year))), pch=16, inset=c(-0.2,0))
par(bg="white", mar=c(5.1,4.1,4.1,2.1))Varias paletas de colores pueden ser accedidas, vale la pena mirar ?rainbow para ver algunas.
6.3 Boxplot
par(bg="white", mar=c(5.1,4.1,4.1,2.1)) # Resetea los parámetros de gráfico
boxplot(EVI ~ as.factor(year), data=df, xlab="Year", ylab="EVI", main="Yearly EVI", col="gold",
notch=F)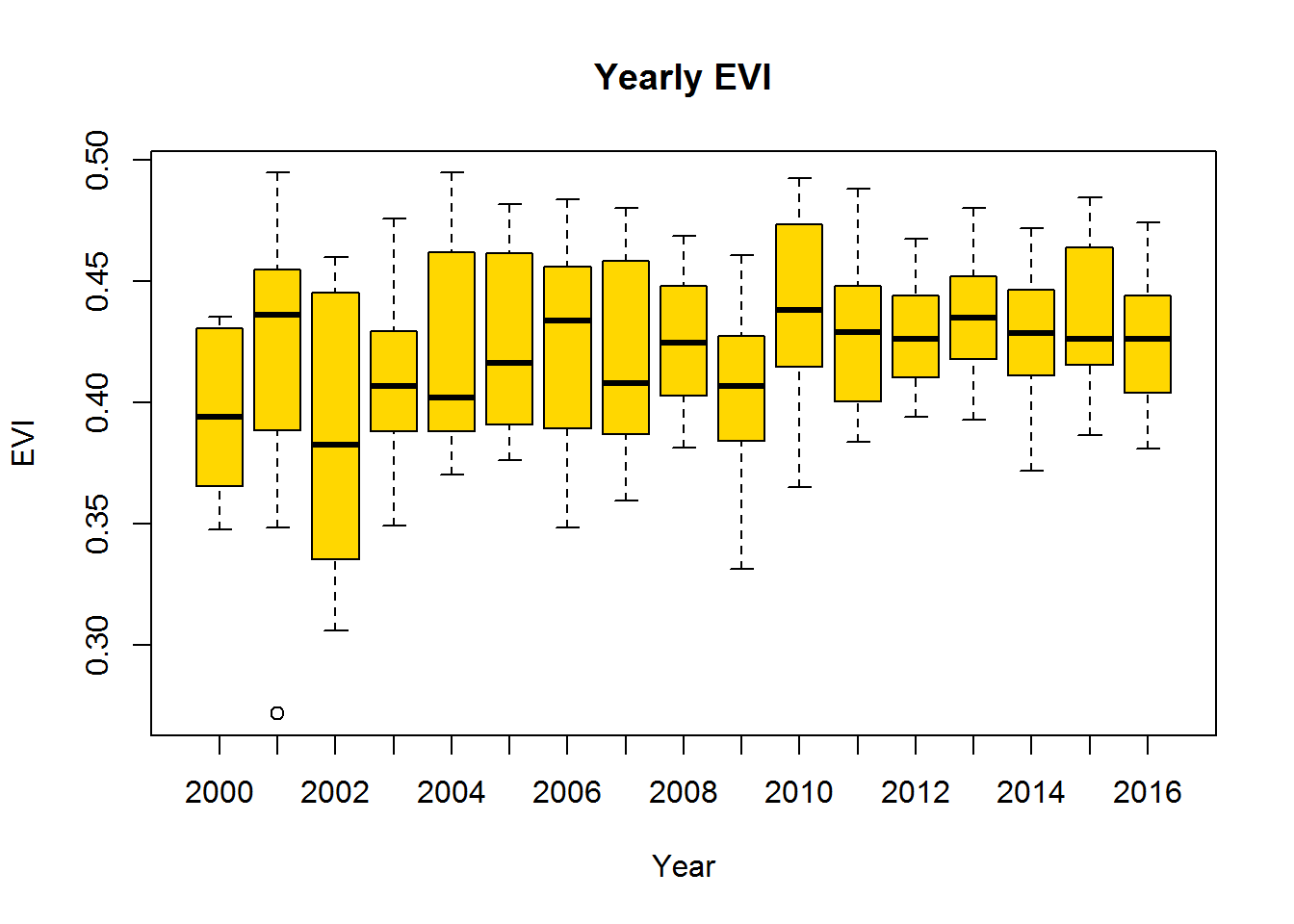
Ahora contra los meses
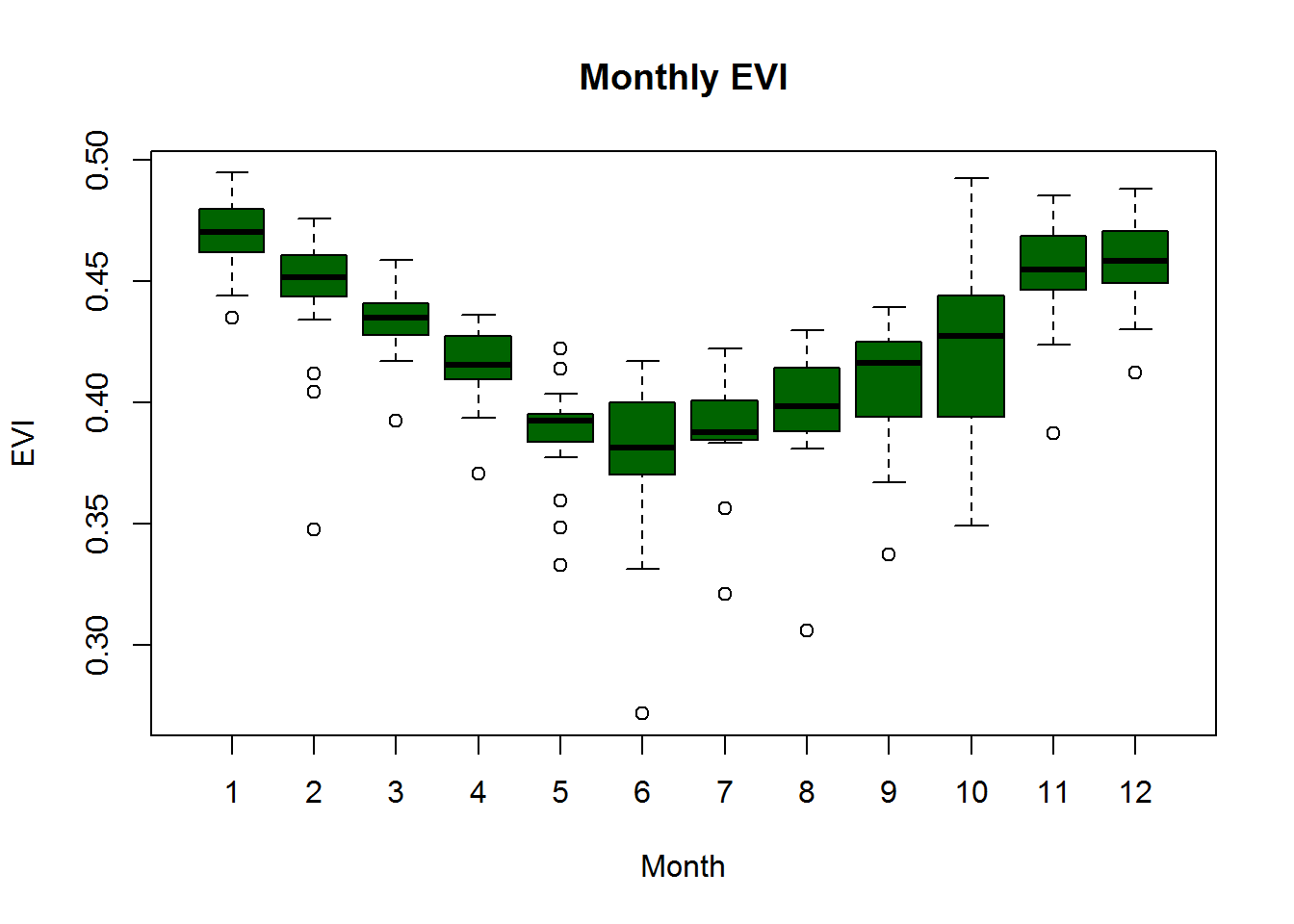
boxplot(EVI ~ as.factor(month), data=df, xlab="Month", ylab="EVI", main="Monthly EVI", col="darkgreen",
varwidth=T, notch=F)